








پردازش تصاویر
پردازش تصاویر
پردازش تصاویر یکی از زمینههای عمده و خاص در پردازش علائم به حساب میآید که در آن دادههای مورد پردازش و عملآوری تصاویر و سیگنالهای دو بعدیست.
پردازش متون
یکی از مسائل عمده در پردازش متون و به طور عمومیتر در پردازش زبانهای طبیعی عملیات و فرایندهای مربوط به مدلسازی دادهها است.
فشردهسازی دادهها
کدگذاری منبع روشهای فشردهسازی یک منبع اطلاعات را مطالعه میکند. منابع اطلاعاتی طبیعی، مانند گفتار یا نوشتار انسانها، دارای افزونگی است؛ برای مثال در جمله «من به خانهمان برگشتم» ضمایر «مان» و شناسه «م» در فعل جمله را میتوان از جمله حذف نمود بدون اینکه از مفموم مورد نظر جمله چیزی کاسته شود. این توضیح را میتوان معادل با انجام عمل فشرده سازی روی اطلاعات یک منبع اطلاعات دانست؛ بنابراین منظور از فشرده سازی اطلاعات کاستن از حجم آن به نحوی است که محتوی آن دچار تغییر نامناسبی نشود.
در علوم کامپیوتر و نظریه اطلاعات، فشرده سازی دادهها یا کد کردن دادهها، در واقع فرایند رمزگذاری اطلاعات با استفاده از تعداد بیتهایی (یا واحدهای دیگر حامل داده) کمتر از آنچه یک تمثال رمزگذاری نشده از همان اطلاعات استفاده میکند و با به کار گرفتن روشهای رمزگذاری ویژهای است.
مانند هر ارتباطی، ارتباطات با اطلاعات فشرده، تنها زمانی کار میکند که هم فرستنده و هم گیرندهٔ اطلاعات، روش رمزگذاری را بفهمند. به عنوان مثال این نوشته تنها زمانی مفهوم است که گیرنده متوجه باشد که هدف پیادهسازی با استفاده از زبان فارسی بوده. به همین ترتیب، دادهٔ فشرده سازی شده تنها زمانی مفهوم است که گیرنده روش رمزگشایی آن را بداند.
فشرده سازی به این دلیل مهم است که کمک میکند مصرف منابع با ارزش، مانند فضای هارد دیسک و یا پهنای باند ارسال، را کاهش دهد. البته از طرفی دیگر، اطلاعات فشرده سازی شده برای اینکه مورد استفاده قرار بگیرند باید از حال فشرده خارج شوند و این فرایند اضافه ممکن است برای بعضی از برنامههای کاربردی زیان آور باشد. برای مثال یک روش فشرده سازی برای یک فیلم ویدئویی ممکن است نیازمند تجهیزات و سختافزار گرانقیمتی باشد که بتواند فیلم را با سرعت بالایی از حالت فشرده خارج سازد که بتواند به طور همزمان با رمزگشایی پخش شود (گزینهای که ابتدا رمزگشایی شود و سپس پخش شود، ممکن است به علت کم بود فضای برای فیلم رمزگشایی شده حافظه امکانپذیر نباشد). بنابراین طراحی روش فشرده سازی نیازمند موازنه و برآیندگیری بین عوامل متعددی است. از جمله این عوامل درصد فشرده سازی، میزان پیچیدگی معرفی شده (اگر از یک روش فشرده سازی پر اتلاف استفاده شود) و منابع محاسباتی لازم برای فشرده سازی و رمزگشایی اطلاعات را میتوان نام برد. فشرده سازی به دو دسته فشردهسازی اتلافی (فشردهسازی با اتلاف) و فشردهسازی بهینه فشردهسازی بیاتلاف اطلاعات تقسیم میشوند. کدگذاری منبع، علم مطالعه روشهای انجام این عمل، برای منابع متفاوت اطلاعاتی موجود است.
فشرده سازی بهینه در مقابل اتلافی
الگوریتمهای فشرده سازی بهینه معمولاً فراوانی آماری را به طریقی به کار میگیرند که بتوان اطلاعات فرستنده را اجمالی تر و بدون خطا نمایش دهند. فشرده سازی بهینه امکانپذیر است چون اغلب اطلاعات جهان واقعی دارای فراوانی آماری هستند. برای مثال در زبان فارسی حرف "الف" خیلی بیش تر از حرف "ژ" استفاده میشود و احتمال اینکه مثلاً حرف "غین" بعد از حرف "ژ" بیاید بسیار کم است. نوع دیگری از فشرده سازی، که فشرده سازی پر اتلاف یا کدگذاری ادراکی نام دارد که در صورتی مفید است که درصدی از صحت اطلاعات کفایت کند. به طور کلی فشرده سازی اتلافی توسط جستجو روی نحوهٔ دریافت اطلاعات مورد نظر توسط افراد راهنمایی میشود. برای مثال، چشم انسان نسبت به تغییرات ظریف در روشنایی حساس تر از تغییرات در رنگ است. فشرده سازی تصویر به روش JPEG طوری عمل میکند که از بخشی از این اطلاعات کم ارزش تر "صرف نظر" میکند. فشرده سازی اتلافی روشی را ارائه میکند که بتوان بیشترین صحت برای درصد فشرده سازی مورد نظر را به دستآورد. در برخی موارد فشرده سازی شفاف (نا محسوس) مورد نیاز است؛ در مواردی دیگر صحت قربانی میشود تا حجم اطلاعات تا حد ممکن کاهش بیابد.
روشهای فشرده سازی بهینه برگشت پذیرند به نحوی که اطلاعات اولیه قابلیت بازیابی به طور دقیق را دارند در حالی که روشهای اتلافی، از دست دادن مقداری از اطلاعات را برای دست یابی به فشردگی بیشتر میپذیرند. البته همواره برخی از داده وجود دارند که الگوریتمهای فشرده سازی بهینهٔ اطلاعات در فشرده سازی آنها ناتوان اند. در واقع هیچ الگوریتم فشرده سازی ای نمیتواند اطلاعاتی که هیچ الگوی قابل تشخیصی ندارند را فشرده سازی کند. بنابراین تلاش برای فشرده سازی اطلاعاتی که قبلاً فشرده شدهاند معمولاً نتیجهٔ عکس داشته (به جای کم کردن حجم، آن را زیاد میکند)، هم چنین است تلاش برای فشرده سازی هر اطلاعات رمز شدهای (مگر حالتی که رمز بسیار ابتدایی باشد).
در عمل، فشرده سازی اتلافی نیز به مرحلهای میرسد که فشرده سازی مجدد دیگر تأثیری ندارد، هرچند یک الگوریتم بسیار اتلافی، مثلاً الگوریتمی که همواره بایت آخر فایل را حذف میکند، همیشه به مرحلهای میرسد که دیگر فایل تهی میشود.
الگوریتمها و برنامههای اجرایی نمونه
مثال فوق مثال بسیار سادهای از یک رمزنگاری الگو-طول (کدبندی طول اجرا، که در آن "الگو" عبارت است از رشتهای از عناصر که به طور متوالی تکرار شده است و "طول" تعداد تکرار آن است) است. این روش اغلب برای بهینهسازی فضای دیسک در کامپیوترهای اداری و یا استفادهٔ بهتر از طول باند اتصال در یک شبکهٔ کامپیوتری به کار میرود. برای دادههای نمادی مانند متنها، صفحه گستردهها ( Spreadsheet)، برنامههای اجرایی و… غیراتلافی بودن ضروری است زیرا تغییر کردن حتی یک بیت داده قابل قبول نمیباشد (مگر در موارد بسیار محدود). برای دادههای صوتی و تصویری کاهش قدری از کیفیت بدون از دست دادن طبیعت اصلی داده قابل قبول میباشد. با بهره بردن از محدودیتهای سیستم حواسی انسان، میتوان در حجم زیادی از فضا صرفه جویی کرد و در عین حال خروجی ای را تولید کرد که با اصل آن تفاوت محسوسی ندارد. این روشهای فشرده سازی اتلافی به طور کلی یک برآیند گیری سه جانبه بین سرعت فشرده سازی، حجم نهایی فشرده سازی و میزان کیفیت قابل چشم پوشی (درصد اتلاف قابل قبول) است.
نظریه
سابقهٔ نظری فشرده سازی برای فشرده سازیهای بهینه توسط نظریهٔ اطلاعات (که رابطه نزدیکی با نظریهٔ اطلاعات الگوریتمی دارد) و برای فشرده سازیهای اتلافی توسط نظریهٔ آهنگ-پیچیدگی ( Rate–distortion theory) ارائه شدهاند. این شاخههای مطالعاتی در اصل توسط کلوده شانون( Claude Shannon)، که مقالاتی بنیادی در این زمینه در اواخر دههای ۱۹۴۰ و اوایل دههٔ ۱۹۵۰ به چاپ رسانده است به وجود آمده. "رمزنگاری" و "نظریهٔ رمزگذاری" نیز رابطه بسیار زیادی با این زمینه دارند. ایدهٔ فشرده سازی رابطهٔ عمیقی با آمار استنباطی دارد.
سطوح سنجش
به کمک سطوح سنجش یا مقیاسها سنجش کیفیت میتوان واقعیتهای مورد مطالعه را دقیقتر سنجید و همچنین امکان ردهبندی درونی اجزای یک جامعه آماری را میسر میسازند. واحدها یا مقیاسهای اندازهگیری که در سنجش کیفیتها بهکار میروند مانند واحدهای کمی مانند متر، دقیقه، مترمکعب، کیفیتها را در سطوج متفاوت میسنجند.
سطوح مقیاسها
مقیاسهای سنجش کیفیتها را به سطوح زیر تقسیمبندی میکنند:
مقیاس اسمی (به انگلیسی: Nominal Scale)
مقیاس ترتیبی (به انگلیسی: Ordinal Scale)
مقیاس فاصلهای (به انگلیسی: Interval Scales)
مقیاس نسبی (به انگلیسی: Ratio Scales)
مقیاسهای اسمی
مقیاس اسمی (Nominal Scale) سادهترین و ابتداییترین مقیاس برای سنجش کیفیتها است.دسته ها ی تقسیمی از لحاظ علامت کوچکتر و یا بزرگتر قابل مقایسه نیستند. به وسیله این مقیاس فقط بودن یا نبودن یک صفت سنجیده میشود.
خصوصیات
امکان تنظیم دادهها براساس اولویت وجود ندارد. به صورتی که افراد جامعه آماری صرفاً براساس دارا بودن یا دارا نبودن یک صفت طبقهبندی میشوند.
هر یک از افراد جامعه آماری تنها به یکی از دو گروه تعلق داشته باشد و هیچیک نمیتواند در هر دو گروه یا هیچ کدام از دو گروه قرار گیرد
کل صفت باید در گروهها قابل بررسی باشد نه بخشی از صفت مثلاً در جامعه آماری افراد یک شهر، ثروت را نمیتوان با این روش ارزیابی کرد.
مقیاس ترتیبی
مقیاسهای ترتیبی (Ordinal Scale) اندکی پیشرفتهتر از مقیاسهای اسمی هستند.
خصوصیات
در این مقیاس در مورد افراد جامعه آماری علاوه بر دارا بودن یا دارا نبودن یک صفت کیفی، شدت و ضعف نسبی مانند کمتر یا بیشتر بودن صفت را نیز بررسی میکند.
در این مقیاس اعداد منسوب به مقولات امکان تنظیم دادهها را با تعیین اولویتها و ترتیبها فراهم میکنند.
اصل بر تمایز و غیر معادل بودن صفتها و ردهبندی براساس اولویت و ترتیب است (برخلاف مقیاسهای اسمی که ویژگی اصلی آنها همارزش بودن مقولههاست)
مقیاسهای فاصلهای
مقیاس فاصلهای (Interval Scale)، مقیاسی با درجات مساوی است مانند دماسنج.
خصوصیات
امکان ردهبندی افراد جامه آماری در دو جهت (از پایین به بالا و از بالا به پائین) وجود دارد
به علت مساوی بودن درجات مقایسه دادهها امکانپذیر است
در مقیاس فاصلهای علاوه بر دارا بودن یا دارا نبودن یک صفت و شدت و ضعف آن در افراد جامعه آماری، میتوان میزان بیشتر یا کمتر بودن یک صفت را بین افراد سنجید.
مقیاسهای نسبی
مقیاسهای نسبی (Ratio Scale) را میتوان در واقع گونهای از مقیاسهای فاصلهای دانست. تنها تفاوت آن با مقیاس فاصلهای این است که مقیاس نسبی دارای نقطه صفر واقعی میباشد. مبدأ سنجش، یک مبدأ واقعی یا به اصطلاح معمول «صفر مطلق» است؛ برای مثال در سنجش جمعیت یک روستا و یا سن و درآمد افراد، مبدأ سنجش صفر واقعی خواهد بود.
آمار مهندسی
آمار مهندسی یکی از شاخههای نوین دانش آمار ریاضی میباشد که مباحث آن بیشتر برای امور کاربردی و عملی پیش بینی شدهاست. آمار مهندسی شامل مباحث متغیرهای تصادفی، احتمالات و پیشامدهای تصادفی و آزمون فرض میباشد.
احتمالات
بطور ساده، احتمالات (به انگلیسی: Probability) به شانس وقوع یک حادثه گفته میشود.
احتمال معمولاً مورد استفاده برای توصیف نگرش ذهن نسبت به گزاره هایی است که ما از حقیقت انها مطمئن نیستیم. گزاره های مورد نظر معمولاً از فرم "آیا یک رویداد خاص رخ می دهد؟" و نگرش ذهن ما از فرم "چقدر اطمینان داریم که این رویداد رخ خواهد داد؟" است. میزان اطمینان ما، قابل توصیف به صورت عددی می باشد که این عدد مقداری بین 0 و 1 را گرفته و آن را احتمال می نا میم. هر چه احتمال یک رویداد بیشتر باشد، ما مطمئن تر خواهیم بود که آن رویداد رخ خواهد داد. درواقع میزان اطمینان ما از اینکه یک واقعه (تصادفی) اتفاق خواهد افتاد.
نظریهٔ احتمالات
نظریهٔ احتمالات به شاخهای از ریاضیات گویند که با تحلیل وقایع تصادفی سروکار دارد.
مانند دیگر نظریه ها، نظریه احتمال نمایشی از مفاهیم احتمال به صورت شرایط صوری (فرمولی) است – شرایطی که میتواند به طور جدا از معنای خود در نظر گرفته شود. این فرمولبندی صوری توسط قوانین ریاضی و منطق دستکاری، ونتیجه های حاصله، تفسیر و یا دوباره به دامنه مسئله ترجمه می شوند.
حداقل دو تلاش موفق برای به بصورت فرمول دراوردن احتمال وجود دار : فرمولاسیون کولموگروف و فرمولاسیون کاکس. در فرمولاسیون کولموگروف (نگاه کنیدبه )، مجموعه ها به عنوان واقعه و احتمالات را به عنوان میزانی روی یک سری از مجموعه ها تفسیرمی کنند. در نظریه کاکس، احتمال به عنوان یک اصل (که هست، بدون تجزیه و تحلیل بیشتر) و تاکید بر روی ساخت یک انتساب سازگار از مقادیر احتمال برای گزاره ها است. در هر دو مورد، قوانین احتمال یکی هستند مگر برای جزئیات تکنیکی مربوط به آنها.
روشهای دیگری نیز برای کمی کردن میزان عدم قطعیت، مانند نظریه Dempster-Shafer theory یا possibility theory وجود دارد ، اما آن ها به طور اساسی با آنچه گفته شد، تفاوت دارند و با درک معمول از قوانین احتمال سازگار نیستند.
تاریخچه
مطالعه علمی احتمال، توسعه ای مدرن است. قمارنشان می دهد که علاقه به ایده های تعیین کمیت برای احتمالات به هزاران سال می رسد، اما توصیفات دقیق ریاضی خیلی دیرتر به وجود آمد. دلایلی البته وجود دارد که توسعه ریاضیات احتمالات را کند می کند. در حالی که بازی های شانس انگیزه ای برای مطالعه ریاضی احتمال بودند، اما مسائل اساسی هنوز هم تحت تاثیر خرافات قماربازان پوشیده می شود.
به گفته ریچارد جفری، "قبل از اواسط قرن هفدهم، اصطلاح ‘’ احتمالی’’ به معنای قابل تایید (تصویب) و در آن معنا چه برای عقیده افراد و چه برای عمل مورد استفاده بود. در واقع افکار یا اقدام احتمالی، رفتاری بود که مردم معقول درآن شرایط از خود نشان می دادند." البته به خصوص در زمینه های قانونی ،احتمالی (به انگلیسی: Probability) همچنین می تواند به گزاره ای که شواهد خوبی برای اثبات آن وجود دارد، اطلاق شود.
گذشته از کار ابتدایی توسط Girolamo Cardano در قرن 16 اصول احتمالات به مکاتبات پیر دو فرما و بلز پاسکال (1654). کریستین هویگنس (1657) اولین مدل شناخته شده علمی از این موضوع را داد. یاکوب برنولی ARS Conjectandi (منتشرشده پس ازمرگ،1713) و اصول شانس Abraham de Moivre (1718) این موضوع را به عنوان شاخه ای از ریاضیات مطرح می کند. برای تاریخچه ای از توسعه های اولیه مفهوم احتمال ریاضی، ظهور احتمال هک ایان و علم حدس جیمز فرانکلین را ببینید.
تئوری خطاها ممکن است از Roger Cotes's Opera Miscellanea (منتشرشده پس ازمرگ،1722) سرچشمه گرفته باشد، اما شرح حالی که توماس سیمپسون در سال 1755 آماده کرد(چاپ 1756)، برای اولین بار اعمال این نظریه به بحث در مورد خطاهای مشاهده است. چاپ مجدد (1757) این شرح حال نشان می دهد که خطاهای مثبت و منفی هر دو به یک اندازه قابل پیشبینی هستند، و با اختصاص برخی از محدودیت های معین، بازه ای برای تمام خطاها ارائه می دهد.سیمپسون همچنین در مورد خطاهای پیوسته بحث می کند و یک منحنی احتمال را توصیف می کند.
پیر سیمون لاپلاس(1774) برای اولین بار سعی دراستنتاج قانونی برای توصیف مشاهدات از نظر اصول تئوری احتمالات کرد. او قانون احتمال خطاها را با یک منحنی به صورت y = \phi(x), x ، x هر نوع خطا و y احتمال آن معرفی می کند و 3 خاصیت برای این منحنی وضع می کند:
نسبت به محور y متقارن است
محور x مجانب است، احتمال خطا در \infty صفر است
مساحت زیر نمودار آن برابر 1 است.
او همچنین، در سال 1781، یک فرمول برای قانون امکان خطا ( اصطلاحی که لاگرانژ سال 1774 مورد استفاده قرار داد) ارائه کرد، اما به معادلات منظمی منجر نشد.
به طور کلی پیدایش فنون و مفاهیم مربوط به احتمالات را باید به آغاز مدلسازی ریاضی و استخراج و اکتشاف دانش در زمینههای پیچیده تر علوم نسبت داد.
تفسیرها و تحلیلهای مفاهیم احتمالات
کلمه احتمال تعریف مفرد مستقیم برای کاربرد عملی ندارد. در واقع، چندین دسته گسترده از تفسیر احتمال، که پیروان دارای دیدگاه های مختلف (و گاهی متضاد) در مورد ماهیت اساسی احتمال وجود دارد.
Frequentists
Subjectivists
Bayesians
کاربردها
نظریه احتمال در زندگی روزمره در ارزیابی ریسک و در تجارت در بازار کالاها اعمال می شود. دولت ها به طور معمول روش های احتمالاتی را در تنظیم محیط زیست اعمال می کنند، که آن را تجزیه و تحلیل مسیر می نامند. یک مثال خوب اثر احتمال هر گونه درگیری گسترده در خاورمیانه بر قیمت نفت است، که اثرات موج واری روی اقتصاد کل جهان می گذارد. ارزیابی که توسط یک معامله گر کالا زمانیکه احتمال جنگ بیشترباشد، در مقابل حالتی که احتمال کمتری دارد، قیمت ها را بالا و پایین می فرستد و معامله گران دیگر را نیز از نظرات خود آگاه می کند. در واقع، احتمالات (در تجارت) به طور مستقل ارزیابی نمیشوند و لزوماً عقلانی نیستند. تئوری های رفتار مالی برای توصیف اثر فکر گروهی در قیمت گذاری ، در سیاست، و در صلح و درگیری ظهور کردند.
می توان گفت که کشف روش های جدی برای سنجش و ترکیب ارزیابی های احتمال، عمیقاً جامعه مدرن را تحت تاثیر قرار داده است. مثلاً اکثر شهروندان اهمیت بیشتری به اینکه چگونه ارزیابی های احتمال وشانس ساخته می شوند، می دهند واینکه تاثیر آنها در تصمیم گیری ها بزرگتر و به ویژه در دموکراسی چگونه است.
یکی دیگر از کاربردهای قابل توجه نظریه احتمال در زندگی روزمره، قابلیت اطمینان می باشد. بسیاری از محصولات مصرفی، از جمله خودروها و لوازم الکترونیکی مصرفی، در طراحی خود به منظور کاهش احتمال خرابی(شکست) از نظریه قابلیت اطمینان استفاده می کنند. تولید کننده با توجه به احتمال خرابی یک محصول، آنرا گارانتی می کند.
علوم اجتماعی
نقش پایه و اساس را برای بیشتر علوم اجتماعی داراست. آزمونهای آماری فواصل اطمینان شیوههای رگرسیون (پس رفت)
نظریه احتمالات
نظریهٔ احتمالات مطالعهٔ رویدادهای احتمالی از دیدگاه ریاضیات است. بعبارت دیگر، نظریه احتمالات به شاخهای از ریاضیات گویند که با تحلیل وقایع تصادفی سروکار دارد. هسته تئوری احتمالات را متغیرهای تصادفی و فرآیندهای تصادفی و پیشامدها تشکیل میدهند. تئوری احتمالات علاوه بر توضیح پدیدههای تصادفی به بررسی پدیدههایی میپردازد که لزوما تصادفی نیستند ولی با تکرار زیاد دفعات آزمایش نتایج از الگویی مشخص پیروی میکنند، مثلاً در آزمایش پرتاب سکه یا تاس با تکرار آزمایش میتوانیم احتمال وقوع پدیدههای مختلف را حدس بزنیم و مورد بررسی قرار دهیم. نتیجه بررسی این الگوها قانون اعداد بزرگ و قضیه حد مرکزی است.
پیشینه
نخستین کتابها را دو دانشمند ایتالیایی درباره بازی با تاس نوشتند: جه رولاموکاردان و گالیلئو گالیله. بااین همه باید آغاز بحث دقیق درباره احتمال را سده هفدهم و با کارهای بلز پاسکال و پییر فرما، ریاضیدانان فرانسوی و کریستین هویگنس هلندی دانست. پاسکال و فرما کتابی در این باره ننوشتند و تنها در نامههای خود به دیگران درباره کاربرد آنالیز ترکیبی در مسالههای مربوط به شانس صحبت کردهاند، ولی هویگنس کتابی با نام بازی با تاس نوشت که اگر چه با کتاب کاردان هم نام است ولی از نظر تحلیل علمی در سطح بسیار بالاتری است. کار آنان توسط یاکوب برنولی و دموآور در قرن هجدهم میلادی ادامه یافت، برنولی کتاب روش حدس زدن را نوشت و قانون عددهای بزرگ را کشف کرد. مساله معروف سوزن نیز در اواسط همین قرن توسط کنت دو بوفون مطرح و حل شد. در سده هجدهم و ابتدای سده نوزدهم نظریه احتمال در دانشهای طبیعی و صنعت به طور جدی کاربرد پیدا کرد. در این دوره نخستین قضیههای نظریه احتمال یعنی قضایای لاپلاس، پواسون، لژاندر و گاوس ثابت شد. در نیمه دوم سده نوزدهم دانشمندان روسی تاثیر زیادی در پیشرفت نظریه احتمال داشتند، چبیشف و شاگردانش، لیاپونوف و مارکوف یک رشته از مسالههای کلی نظریه احتمال را حل کردند و قضایای برنولی و لاپلاس را تعمیم دادند. در آغاز قرن بیستم متخصصان کارهای قبلی را منظم نموده و ساختمان اصول موضوعه احتمال را بنا نمودند. در این دوره دانشمندان زیادی روی نظریه احتمال کار کردند: در فرانسه، بورل، لهوی و فرهشه؛ در آلمان، میزس؛ در آمریکا، وینر، فه لر و دوب؛ در سوئد، کرامر؛ در شوروی، خین چین، سلوتسکی، رومانوسکی، سمپرنوف، گنه دنکو اما درخشانترین نام در این عرصه کولموگروف روسی است که اصول موضوع احتمال را در کتابی به نام مبانی تئوری احتمال در آلمان منتشر کرد.
مفهوم
مفهوم احتمال در مورد ارتباط یا پیوند دو متغیر به کار میرود، به این معنی که ارتباط یا پیوند آنها به صورتی است که حضور، شکل، وسعت و اهمیت هر یک وابسته به حضور، شکل، و اهمیت دیگری است. این مفهوم به صورت محدودتر و در مورد ارتباط دو متغیر کمّی نیز بهکار برده میشود.
آزمایش تصادفی
به آزمایشی گفته میشود که نتیجه آن قبل از انجام آزمایش مشخص نیست و بتوان آن آزمایش را در شرایط یکسان و به دفعات دلخواه انجام داد.
فضای نمونه
به مجموعهای از تمام نتایج ممکن در یک آزمایش تصادفی فضای نمونه میگویند.
کاربرد احتمال در زندگی
یک تأثیر مهم نظریه احتمال در زندگی روزمره در ارزیابی ریسک پذیری و در تجارت در مورد خرید و فروش اجناس میباشد. حکومتها به طور خاص روشهای احتمال را در تنظیم جوامع اعمال میکنند که به عنوان «آنالیز خط مشی» نامیده میشود و غالباً سطح رفاه را با استفاده از متدهایی که در طبیعت تصادفی اند اندازه میگیرند و برنامههایی را انتخاب میکنند تا اثر احتمال آنها را روی جمعیت به صورت کلی از نظر آماری ارزیابی کنند. این گفته صحیح نیست که آمار، خود در مدل سازی درگیر هست زیرا که ارزیابیهای میزان ریسک وابسته به زمان هستند و بنابراین مستلزم مـدلهای احتمال قوی تر هستند؛ مثلاً «احتمال۹/۱۱ دیگری»؛ قانون اعداد کوچک در جنین مواردی اعمال میشود و برداشت اثر چنین انتخابهایی است که روشهای آماری را به صورت یک موضوع سیاسی در میآورد.
یک مثال خوب اثر احتمال قلمداد شده از مجادلات خاورمیانه بر روی قیمت نفت است که دارای اثرات متلاطمی از لحظ آماری روی اقتصاد کلی دارد. یک ارزیابی توسط یک واحد تجاری در مورد این که احتمال وقوع یک جنگ زیاد است یا کم باعث نوسان قیمتها میشود و سایر تجار را برای انجام کار مشابه تشویق میکند. مطابق با این اصل، احتمالات به طور مستقل ارزیابی نمیشوند و ضرورتاً به طور منطقی برخورد صورت نمیگیرد. نظریه اعتبارات رفتاری، به وجود آمدهاست تا اثر این تفکرات گروهی را روی قیمتها، سیاستها و روی صلح و مجادله توضیح دهد.
به طور استدلالی میتوان گفت که کشف روشهای جدی برای ارزیابی و ترکیب ارزیابیهای احتمالی دارای اثر شدیدی روی جامعه مدرن داشتهاست. یک مثال خوب کاربرد نظریه بازیها که به طور بنیادین بر پایه احتمال ریخته شدهاست در مورد جنگ سرد و دکترین انهدام با اطمینان بخشی متقابل است. مشابهاً ممکن است برای اغلب شهروندان دارای اهمیت باشد که بفهمند چگونه بختها و ارزیابیهای احتمال صورت میگیرد و چگونه آنها میتوانند در تصمیم گیریها به ویژه در زمینه دموکراسی دخالت کنند.
کاربرد مهم دیگر نظریه احتمال در زندگی روزمره، اعتبار است. اغلب تولیدات مصرفی مثل اتومبیل و وسایل الکترونیکی در طراحی آنها از نظریه اعتبار استفاده میشود به نحوی که احتمال نقص آنها کاهش یابد. احتمال نقص با مدت ضمانت فرآورده معمولاً ارتباط نزدیک دارد.
نقد ها
تصمیم گیری یا عدم تصمیم گیری
یکی از نقد هایی که به نظریه ی احتمال وارد است، مبتنی بودن آن بر فراوانی نسبی یک پیشامد به عنوان احتمال رخداد آن است. به دیگر بیان، نظریه احتمال، احتمال رخداد یک پیشامد را معادل با ایمان ما نسبت به رخداد آن پدیده می داند و ایمان به نسبت به رخداد آن پیشامد را معادل فراوانی نسبی آن پدیده در یک آزمایش آماری میداند.. در این اعتقاد دو ایراد فلسفی وجود دارد: اولا: ایمان ما نسبت به رخداد یک پیشامد برابر با احتمال رخداد پیشامد در نظر گرفته شده است. این به این معناست که ایمان درونی انسان به رخداد یک پیشامد برابر با احتمال حقیقتی است که در بیرون رخ خواهد داد. که این تطابق، فاقد هر گونه توجیه منطقی است. ثانیا: احتمال رخداد را برابر با فراوانی نسبی آن پیشامد در آزمایش آماری در نظر می گیرد که این نیز محل بحث است. به عنوان مثال فرض کنید که شما در بازی قماری شرکت کرده اید که با محاسبه ی احتمال ها بر اساس تئوری موجود، احتمال پیروزی شما 2/3 است. لذا سرمایه گذاری در این قمار در 2/3 اوقات به نفع شماست. فرض کنید که بازی 15 دور است. در این صورت شما باید 10 دور این بازی را احتمالا پیروز شوید. شما بازی را شروع می کنید و تا دور 11_ام شکست می خورید و و دور 12 را می برید و دور 13 و 14 را شکست می خورید و دور 15_ام را می برید. این اتفاق یک اتفاق کاملا "ممکن" است. در این صورت شما 0.36- = 13/15 - 1/2 واحد از سرمایه ی خود را از دست داده اید. توجیهی که احتمال دان ها می آورند این است: "اگر تعداد دور ها به بی نهایت میل می کرد شما در 2/3 حالات برنده بودید." در صورتی که در جهان واقعی هیچ گاه بازی هایی با تعداد دور بی نهایت وجود ندارد." در تصمیم گیری های اجتماعی و سیاسی نیز همین امر برقرار است. ریسک سرمایه گزاری بر اساس این نظریه در نظر گرفتنی است. اما این مساله و شبیه این مساله ها با "نظریه امکان" با دیدگاهی کاملا منطقی قابل بررسی، تحلیل و تصمیم گیری است.
عدم وجود تصادف
باور به تئوری احتمال در تمامی ابعاد مستلزم باور به تصادف است. در حالی که هنوز بشر هیچ پدیده ی تصادفی را اطراف خود ندیده است!!! آن فرآیند هایی که موسوم به فرایند تصادفی هستند به سه دسته عمده تقسیم می شوند:
1- فرآیند هایی که از حیث پیچیدگی مقرون به صرفه ترند که با آنها با دیدگاه تصادفی نگاه کرد. مانند جدا شدن اتم های کربن در فضای آزاد. یا پیشامد فرو ریختن پل در حالتی که بار روی پل استاتیکی می شود.
2- فرآیند هایی که تصادفی بودن آنها صرفا به علت عدم علم و عدم توانایی دسترسی ما به علت دقیق آن پیشامدها است. مانند اصل عدم قطعیت هایزنبرگ
3- فرآیند هایی که تصادفی بودن آنها به علت وجود اراده ی یک موجود مختار است. مانند پرتاب یک سکه. و یا اکثر فرایند های اجتماعی و انسانی.
درصورتی که در هر سه حالت بالا با شرط آگاهی ما از مکانیزم دقیق پیشامد، پسوند "تصادفی" خود به خود حذف می شود. اگر بدانیم که تمام نیرو هایی که بر پل وارد می شوند به چه صورت است، اگر "ببینیم" که حرکت دقیق ذرات بنیادین به چه صورت است، اگر مکانیک پرتاب یک سکه را در هر تعداد مرتبه ی دلخواه به ازای هر مقدار نیرو که پرتاب کننده اراده می کند، فرموله کنیم و قص علی هذا، هیچ فرایند تصادفی وجود نخواهد داشت. چه برسد که این تصادف فرموله شود و بر مبنای نتایج محاسبات آنها، تصمیم گیری شود.
اعداد تصادفی
اعداد تصادفی در ریاضی، عبارتند از خروجیهایی که از پیش تعیین نشدهاند. این دسته اعداد برای امتحان شانس و همچنین برای امتحان حاصل کردن برنامهها به کار میروند. انسانها قابلیت محاسبه اعداد تصادفی را ندارند.
کاربرد در محاسبات
برای به دست آوردن مقادیر تصادفی در ماشین حسابها و برنامه نویسی از متد تایمر استفاده میشود. برای مثال، اکس ثانیه، عدد(۷.)۹ را در خروجی نمایش میدهد، که میتواند به صورت زیر نوشته شود:(زبان برنامه: Visual Basic ۶)
Dim rNum as Long
MyRN.Caption = Rnd(rNum) * 10
هر بار برنامه اجرا میگردد، تایمر از صفر شروع میشود و یک سری اعداد نمایان هر دفعه تکرار میشوند. برای جلوگیری از تکرار این حلقهها، معمولاً از دستور Randomize استفاده میگردد. در این حالت، در هر اجرا اعداد متفاوتی خواهیم داشت:
Dim rNum as Long
Randomize
MyRN.Caption = Rnd(rNum) * 10
درکنار این مبحث، حروف تصادفی نیز وجود دارند. آنها شامل حروف بزرگ ویا کوچک میشوند. حروف غیر استاندارد هم در این مجموعه قرار میگیرند.
توان آماری
توان یک آزمون آماری احتمال رد کردن فرض صفر اشتباه میباشد (احتمال آنکه تست آماری مرتکب خطای نوع دوم نشود). هر چه توان یک تست بیشتر باشد احتمال وقوع خطای نوع دوم کمتر خواهد بود.
محققان همیشه نگران این بوده اند که نکند فرضیه صفر را رد کنند در حالی که در واقع درست بوده است (تست آماری مرتکب خطای نوع یک شود) یا اینکه نتوانند فرضیه صفر را رد کنند در حالی که این روش های استفاده شده بوده اند که اثری واقعی داشتهاند (تست آماری مرتکب خطای نوع دو شود). توان آماری یک تست، احتمال آن است که منجر به این میشود که شما فرضیه صفر را رد کنید وقتی فرضیه در واقع غلط است. چون بیشتر تست های امری در شرایطی انجام میشوند که عامل اصلی(treatment)، حداقل کمی اثر روی نتیجه دارد، توان آماری به صورت احتمال اینکه آن تست "منجر به نتیجه گیری درستی در مورد فرضیه صفر میشود"، تعبیر میشود.
توان یک تست آماری عبارت است از: یک، منهای احتمال ایجاد خطای نوع دو. یا به عبارتی، احتمال اینکه شما از خطای نوع دو دوری میکنید.
در مطالعات با توان آماری بالا، خیلی کم پیش میاید که در تشخیص اثرات تمرین اشتباه کنند.
توان یک تست آماری، شامل عملکردِ: حساسیت، اندازه اثر در جمیعت آماری، و استاندارد های استفاده شده برای اندازه گیری فرضیه آماری است. - ساده ترین راه برای افزایش حساسیت یک تحقیق، افزایش تعداد آزمودنی هاست. - در مورد استاندارد، ساده تر آن است که فرضیه صفر را رد کنیم اگر سطح معناداری، ۰.۰۵ باشد تا ۰.۰۱ یا ۰.۰۰۱.
سه قدم برای تعین توان آماری: ۱- مشخص کردن حد، برای معنی دار بودن آماری. فرضیه چیست؟ سطح معناداری چقدر است؟
۲- حدس زدن اندازه اثر. انتظار دارد که درمان(treatment)، دارای اثری کم، زیاد، یا متوسط باشد؟
توزیع احتمال
در نظریه احتمال و آمار تابع توزیع احتمال بیانگر احتمال هر یک از مقادیر متغیر تصادفی (در مورد متغیر گسسته) و یا احتمال قرار گرفتن متغیر در یک بازه مشخص (در مورد متغیر تصادفی پیوسته) میباشد. توزیع تجمعی احتمال یک متغیر تصادفی تابعی است از دامنهٔ آن متغیر بر بازهٔ 0,1. به طوری که احتمال رخدادن پیشامدهای با مقدار عددی کمتر از آن را نمایش میدهد.
توزیع احتمالی گسسته
در آمار و احتمالات، به دستهای از توزیعها توزیع گسسته گویند که در آنها متغیر تصادفی تنها میتواند تعداد محدود و یا تعداد شمارایی از مقادیر را اختیار کند.
تولید اعداد تصادفی
یک تولیدکننده اعداد تصادفی (به انگلیسی: Random Number Generation، بهاختصار:RNG) وسیلهای فیزیکی و یا روشی محاسباتی است که برای تولید دنبالهای از اعداد که الگوی خاصی ندارند (یعنی بطور تصادفی ظاهر شدهاند) به کار میرود.
سامانههای رایانهای بطور گسترده برای تولید اعداد تصادفی مورد استفاده قرار میگیرند در حالیکه تولید کنندههای خوبی نیستند هرچند الگوهای آنها به راحتی قابل تشخیص نیست.
از زمانهای قدیم روشهایی برای تولید این اعداد وجود داشتهاست از جمله پرتاب تاس، پرتاب سکه و برهم زدن کارتها که همچنان در بازیها و قمارخانهها مورداستفاده قرار میگیرند. در واقع کاربرد بسیار این اعداد موجب گوناگونی و فراوانی روشهای تولید این اعداد (از لحاظ مدت زمانی که برای تولید این اعداد سپری میشود و الگوهای مورد استفاده آنها) شدهاست.
روشهای فیزیکی
برخی از پدیدههای طبیعی الگوهای مناسبی برای تولید این اعداد هستند به عنوان مثال برخی پدیدههای فیزیکی از جمله اختلالات حرارتی در دیودهای زنر (Zener Diodes) دارای رفتاری کاملاً تصادفی هستند و میتوانند پایهای برای تولید RNGهای فیزیکی و سختافزاری باشند.
همانطور که اشاره شد، الگوهای طبیعی جالبی برای تولید اعداد تصادفی وجود دارد؛ یک روش متداول استفاده از یک تابع درهم ساز (که ورودی اش جریانی از فریمهای ویدئوییٍ یک منبع غیر قابل پیش بینی میباشد) است. به عنوان مثال لاواراند (Lavarand)از تصاویر تعدادی لامپ لاوا(Lava Lamps) استفاده کرد. Lithium Technologies از تصاویر آسمان و Random.org از صداهای آشفته جوی استفاده میکند.
روشهای محاسبهای
تولیدکنندههای اعداد شبه تصادفی الگوریتمهایی با قابلیت تولید اعداد تصادفی هستند هرچند اعداد تولید شده توسط آنها به طور تناوبی تکرار میشود و یا آنکه حافظه زیادی را اشغال میکنند.
یک روش ساده که با قلم و کاغذ نیز قابل اجراست روش میانه مربع (Middle Square Method) است که توسط جان فون نیومن (John Von Neumann) ابداع شد که بسیار سادهاست ولی اعداد تولیدی آن از لحاظ آماری کیفیت خوبی ندارند.
بسیاری از زبانهای برنامهنویسی رایانه شامل توابع کتابخانهای هستند که برای تولید اعداد تصادفی (یک بایت، کلمه ویا اعداداعشاری تصادفی با توزیع یکنواخت بین ۰ و ۱)طراحی شدهاند. این توابع کتابخانهای اغلب از لحاظ خصوصیات آماری ضعیف هستند و الگوهایشان پس از تنها ۱۰۰۰ رشته دوباره تکرار میشود، آنها اغلب با زمان واقعی رایانه به عنوان seed راهاندازی میشوند. در واقع این توابع در بعضی موارد به تعداد کافی رویداد تصادفی تولید میکنند (مثلاً در بازیهای ویدئویی) ولی وقتی رویدادهای تصادفی با کیفیت بالا مورد نظر است، ناکارآمد هستند (مثلاً در رمزنگاری).
کاربردهای اعداد تصادفی
شبیهسازی: وقتی یک رایانه برای شبیهسازی مفاهیم طبیعی مورد استفاده قرار میگیرد، اعداد تصادفی برای واقعی نشان دادن اجزا و رویدادها مورد نیاز هستند. شبیهسازی بسیاری از رشته هارا پوشش میدهد مثلاً فیزیک هستهای
نمونهبرداری: آزمودن همه حالات ممکن برای یک سامانه اغلب غیر عملی است اما وضعیت و درستی یک نمونه تصادفی میتواند حالت کلی سیستم را شرح دهد.
آنالیز عددی: روشهای مبتکرانهای برای حل مسائل عددی پیچیده ابداع شدهاست که از اعداد تصادفی استفاده میکنند.
کتابهای بسیاری نیز در همین مورد نوشته شدهاند.
برنامهنویسی رایانهای: مقادیر تصادفی منابع خوبی از اطلاعات برای تست کردن کارایی الگوریتمهای کامپیوتری هستند؛ از همه مهمتر نقش آنها در اجرای الگوریتمهای تصادفی است.
تصمیمگیری: گزارشهایی مبنی براینکه برخی مدیران اجرایی تصمیمات خود را برپایه پرتاب سکه و یا دارت میگیرند؛ در واقع بعضی وقتها باید بدون غرضورزی تصمیمات گرفته شوند.
تولید اعداد تصادفی در رایانه
از آنجاییکه رایانهها ماشینهایی از نوع معیّن (Deterministic) هستند، با دریافت ورودی یکسان، همیشه یک خروجی بیرون میدهند. ازین رو تولید اعداد تصادفی در رایانه مبحثی است
در زبانهای برنامهنویسی گوناگون، تابعی وجود دارد که عددی تصادفی و معمولاً در بازهٔ صفر و یک تولید میکند. این تابع باید به گونهای باشد که با چند بار تولید عدد تصادفی کاربر قادر به حدس زدن و پیدا کردن قاعده و الگویی در ایجاد این اعداد نشود.
هر بار که این تابع صدا زده میشود، رایانه عدد تولید شدهٔ پیشین را به عنوان ورودی جدید تابع تولید عدد تصادفی میفرستد. منشاء مشکل نیز در همین مرحله است.
هر بار که این تابع صدا زده شود، بر اساس ماهیت جبری ماشین و با توجه به مقدار اولیهٔ فرستاده شده به تابع تولید عدد تصادفی (seed) باید با یک دنباله از اعداد مشابه یکدیگر مواجه شویم.
چگونه مقدار اولیه مناسب را پیدا کنیم؟
در برنامهنویسی به عنوان مثال برای نوشتن یک بازی راهحلهای گوناگونی مانند قرار دادن مقدار اولیه برابر با تعداد بازیهای انجام شده بر روی رایانه و یا ذخیرهٔ خروجی آخرین seed از برنامهٔ قبلی در حال اجرا است. با اینحال کماکان مشکل مقدار دهی اولین seed پابرجاست.
اولین مقدار اولیه
راحتترین راه حل این مسأله در دنیای کامپیوتر استفاده از زمان فعلی دستگاه است. کامپیوترهای امروزی زمان را با دقت میلیثانیه در دسترس دارند. برنامهها میتوانند زمان اولین اجرای خود را به عنوان seed به اولین باری که تابع تولید اعداد تصادفی صدا زده میشود، بفرستند. ولی اگر باز هم دونفر به طور کاملاً همزمان برنامه را اجرا کنند خروجی یکسان دریافت خواهند کرد. این مشکل هم با افزودن معیارهای دیگری به seed مانند زمان آخرین کلیک موشی (Mouse Click)، مدت زمان بالا بودن سیستمعامل و مواردی مشابه، به مقدار زیادی کاهش داد. با افزودن این معیارها و معیارهای مشابه دیگر به برنامه احتمال ایجاد تشابه را به سمت صفر کاهش میدهیم.
در همان زبان برنامهنویسی جاوا که به عنوان نمونه آورده شد، ورودی Constructor یک عدد از نوع اولیهٔ long به عنوان ورودی میگیرد. این عدد long یک عدد ۶۴ بیتی در جاوا است که خود باعث محدود شدن seed و امکان به وجود آمدن اعداد تصادفی برابر را فراهم میسازد. بنابر این مشکل کاملاً حل نشدهاست.
پردازش تصاویر یکی از زمینههای عمده و خاص در پردازش علائم به حساب میآید که در آن دادههای مورد پردازش و عملآوری تصاویر و سیگنالهای دو بعدیست.
پردازش متون
یکی از مسائل عمده در پردازش متون و به طور عمومیتر در پردازش زبانهای طبیعی عملیات و فرایندهای مربوط به مدلسازی دادهها است.
فشردهسازی دادهها
کدگذاری منبع روشهای فشردهسازی یک منبع اطلاعات را مطالعه میکند. منابع اطلاعاتی طبیعی، مانند گفتار یا نوشتار انسانها، دارای افزونگی است؛ برای مثال در جمله «من به خانهمان برگشتم» ضمایر «مان» و شناسه «م» در فعل جمله را میتوان از جمله حذف نمود بدون اینکه از مفموم مورد نظر جمله چیزی کاسته شود. این توضیح را میتوان معادل با انجام عمل فشرده سازی روی اطلاعات یک منبع اطلاعات دانست؛ بنابراین منظور از فشرده سازی اطلاعات کاستن از حجم آن به نحوی است که محتوی آن دچار تغییر نامناسبی نشود.
در علوم کامپیوتر و نظریه اطلاعات، فشرده سازی دادهها یا کد کردن دادهها، در واقع فرایند رمزگذاری اطلاعات با استفاده از تعداد بیتهایی (یا واحدهای دیگر حامل داده) کمتر از آنچه یک تمثال رمزگذاری نشده از همان اطلاعات استفاده میکند و با به کار گرفتن روشهای رمزگذاری ویژهای است.
مانند هر ارتباطی، ارتباطات با اطلاعات فشرده، تنها زمانی کار میکند که هم فرستنده و هم گیرندهٔ اطلاعات، روش رمزگذاری را بفهمند. به عنوان مثال این نوشته تنها زمانی مفهوم است که گیرنده متوجه باشد که هدف پیادهسازی با استفاده از زبان فارسی بوده. به همین ترتیب، دادهٔ فشرده سازی شده تنها زمانی مفهوم است که گیرنده روش رمزگشایی آن را بداند.
فشرده سازی به این دلیل مهم است که کمک میکند مصرف منابع با ارزش، مانند فضای هارد دیسک و یا پهنای باند ارسال، را کاهش دهد. البته از طرفی دیگر، اطلاعات فشرده سازی شده برای اینکه مورد استفاده قرار بگیرند باید از حال فشرده خارج شوند و این فرایند اضافه ممکن است برای بعضی از برنامههای کاربردی زیان آور باشد. برای مثال یک روش فشرده سازی برای یک فیلم ویدئویی ممکن است نیازمند تجهیزات و سختافزار گرانقیمتی باشد که بتواند فیلم را با سرعت بالایی از حالت فشرده خارج سازد که بتواند به طور همزمان با رمزگشایی پخش شود (گزینهای که ابتدا رمزگشایی شود و سپس پخش شود، ممکن است به علت کم بود فضای برای فیلم رمزگشایی شده حافظه امکانپذیر نباشد). بنابراین طراحی روش فشرده سازی نیازمند موازنه و برآیندگیری بین عوامل متعددی است. از جمله این عوامل درصد فشرده سازی، میزان پیچیدگی معرفی شده (اگر از یک روش فشرده سازی پر اتلاف استفاده شود) و منابع محاسباتی لازم برای فشرده سازی و رمزگشایی اطلاعات را میتوان نام برد. فشرده سازی به دو دسته فشردهسازی اتلافی (فشردهسازی با اتلاف) و فشردهسازی بهینه فشردهسازی بیاتلاف اطلاعات تقسیم میشوند. کدگذاری منبع، علم مطالعه روشهای انجام این عمل، برای منابع متفاوت اطلاعاتی موجود است.
فشرده سازی بهینه در مقابل اتلافی
الگوریتمهای فشرده سازی بهینه معمولاً فراوانی آماری را به طریقی به کار میگیرند که بتوان اطلاعات فرستنده را اجمالی تر و بدون خطا نمایش دهند. فشرده سازی بهینه امکانپذیر است چون اغلب اطلاعات جهان واقعی دارای فراوانی آماری هستند. برای مثال در زبان فارسی حرف "الف" خیلی بیش تر از حرف "ژ" استفاده میشود و احتمال اینکه مثلاً حرف "غین" بعد از حرف "ژ" بیاید بسیار کم است. نوع دیگری از فشرده سازی، که فشرده سازی پر اتلاف یا کدگذاری ادراکی نام دارد که در صورتی مفید است که درصدی از صحت اطلاعات کفایت کند. به طور کلی فشرده سازی اتلافی توسط جستجو روی نحوهٔ دریافت اطلاعات مورد نظر توسط افراد راهنمایی میشود. برای مثال، چشم انسان نسبت به تغییرات ظریف در روشنایی حساس تر از تغییرات در رنگ است. فشرده سازی تصویر به روش JPEG طوری عمل میکند که از بخشی از این اطلاعات کم ارزش تر "صرف نظر" میکند. فشرده سازی اتلافی روشی را ارائه میکند که بتوان بیشترین صحت برای درصد فشرده سازی مورد نظر را به دستآورد. در برخی موارد فشرده سازی شفاف (نا محسوس) مورد نیاز است؛ در مواردی دیگر صحت قربانی میشود تا حجم اطلاعات تا حد ممکن کاهش بیابد.
روشهای فشرده سازی بهینه برگشت پذیرند به نحوی که اطلاعات اولیه قابلیت بازیابی به طور دقیق را دارند در حالی که روشهای اتلافی، از دست دادن مقداری از اطلاعات را برای دست یابی به فشردگی بیشتر میپذیرند. البته همواره برخی از داده وجود دارند که الگوریتمهای فشرده سازی بهینهٔ اطلاعات در فشرده سازی آنها ناتوان اند. در واقع هیچ الگوریتم فشرده سازی ای نمیتواند اطلاعاتی که هیچ الگوی قابل تشخیصی ندارند را فشرده سازی کند. بنابراین تلاش برای فشرده سازی اطلاعاتی که قبلاً فشرده شدهاند معمولاً نتیجهٔ عکس داشته (به جای کم کردن حجم، آن را زیاد میکند)، هم چنین است تلاش برای فشرده سازی هر اطلاعات رمز شدهای (مگر حالتی که رمز بسیار ابتدایی باشد).
در عمل، فشرده سازی اتلافی نیز به مرحلهای میرسد که فشرده سازی مجدد دیگر تأثیری ندارد، هرچند یک الگوریتم بسیار اتلافی، مثلاً الگوریتمی که همواره بایت آخر فایل را حذف میکند، همیشه به مرحلهای میرسد که دیگر فایل تهی میشود.
الگوریتمها و برنامههای اجرایی نمونه
مثال فوق مثال بسیار سادهای از یک رمزنگاری الگو-طول (کدبندی طول اجرا، که در آن "الگو" عبارت است از رشتهای از عناصر که به طور متوالی تکرار شده است و "طول" تعداد تکرار آن است) است. این روش اغلب برای بهینهسازی فضای دیسک در کامپیوترهای اداری و یا استفادهٔ بهتر از طول باند اتصال در یک شبکهٔ کامپیوتری به کار میرود. برای دادههای نمادی مانند متنها، صفحه گستردهها ( Spreadsheet)، برنامههای اجرایی و… غیراتلافی بودن ضروری است زیرا تغییر کردن حتی یک بیت داده قابل قبول نمیباشد (مگر در موارد بسیار محدود). برای دادههای صوتی و تصویری کاهش قدری از کیفیت بدون از دست دادن طبیعت اصلی داده قابل قبول میباشد. با بهره بردن از محدودیتهای سیستم حواسی انسان، میتوان در حجم زیادی از فضا صرفه جویی کرد و در عین حال خروجی ای را تولید کرد که با اصل آن تفاوت محسوسی ندارد. این روشهای فشرده سازی اتلافی به طور کلی یک برآیند گیری سه جانبه بین سرعت فشرده سازی، حجم نهایی فشرده سازی و میزان کیفیت قابل چشم پوشی (درصد اتلاف قابل قبول) است.
نظریه
سابقهٔ نظری فشرده سازی برای فشرده سازیهای بهینه توسط نظریهٔ اطلاعات (که رابطه نزدیکی با نظریهٔ اطلاعات الگوریتمی دارد) و برای فشرده سازیهای اتلافی توسط نظریهٔ آهنگ-پیچیدگی ( Rate–distortion theory) ارائه شدهاند. این شاخههای مطالعاتی در اصل توسط کلوده شانون( Claude Shannon)، که مقالاتی بنیادی در این زمینه در اواخر دههای ۱۹۴۰ و اوایل دههٔ ۱۹۵۰ به چاپ رسانده است به وجود آمده. "رمزنگاری" و "نظریهٔ رمزگذاری" نیز رابطه بسیار زیادی با این زمینه دارند. ایدهٔ فشرده سازی رابطهٔ عمیقی با آمار استنباطی دارد.
سطوح سنجش
به کمک سطوح سنجش یا مقیاسها سنجش کیفیت میتوان واقعیتهای مورد مطالعه را دقیقتر سنجید و همچنین امکان ردهبندی درونی اجزای یک جامعه آماری را میسر میسازند. واحدها یا مقیاسهای اندازهگیری که در سنجش کیفیتها بهکار میروند مانند واحدهای کمی مانند متر، دقیقه، مترمکعب، کیفیتها را در سطوج متفاوت میسنجند.
سطوح مقیاسها
مقیاسهای سنجش کیفیتها را به سطوح زیر تقسیمبندی میکنند:
مقیاس اسمی (به انگلیسی: Nominal Scale)
مقیاس ترتیبی (به انگلیسی: Ordinal Scale)
مقیاس فاصلهای (به انگلیسی: Interval Scales)
مقیاس نسبی (به انگلیسی: Ratio Scales)
مقیاسهای اسمی
مقیاس اسمی (Nominal Scale) سادهترین و ابتداییترین مقیاس برای سنجش کیفیتها است.دسته ها ی تقسیمی از لحاظ علامت کوچکتر و یا بزرگتر قابل مقایسه نیستند. به وسیله این مقیاس فقط بودن یا نبودن یک صفت سنجیده میشود.
خصوصیات
امکان تنظیم دادهها براساس اولویت وجود ندارد. به صورتی که افراد جامعه آماری صرفاً براساس دارا بودن یا دارا نبودن یک صفت طبقهبندی میشوند.
هر یک از افراد جامعه آماری تنها به یکی از دو گروه تعلق داشته باشد و هیچیک نمیتواند در هر دو گروه یا هیچ کدام از دو گروه قرار گیرد
کل صفت باید در گروهها قابل بررسی باشد نه بخشی از صفت مثلاً در جامعه آماری افراد یک شهر، ثروت را نمیتوان با این روش ارزیابی کرد.
مقیاس ترتیبی
مقیاسهای ترتیبی (Ordinal Scale) اندکی پیشرفتهتر از مقیاسهای اسمی هستند.
خصوصیات
در این مقیاس در مورد افراد جامعه آماری علاوه بر دارا بودن یا دارا نبودن یک صفت کیفی، شدت و ضعف نسبی مانند کمتر یا بیشتر بودن صفت را نیز بررسی میکند.
در این مقیاس اعداد منسوب به مقولات امکان تنظیم دادهها را با تعیین اولویتها و ترتیبها فراهم میکنند.
اصل بر تمایز و غیر معادل بودن صفتها و ردهبندی براساس اولویت و ترتیب است (برخلاف مقیاسهای اسمی که ویژگی اصلی آنها همارزش بودن مقولههاست)
مقیاسهای فاصلهای
مقیاس فاصلهای (Interval Scale)، مقیاسی با درجات مساوی است مانند دماسنج.
خصوصیات
امکان ردهبندی افراد جامه آماری در دو جهت (از پایین به بالا و از بالا به پائین) وجود دارد
به علت مساوی بودن درجات مقایسه دادهها امکانپذیر است
در مقیاس فاصلهای علاوه بر دارا بودن یا دارا نبودن یک صفت و شدت و ضعف آن در افراد جامعه آماری، میتوان میزان بیشتر یا کمتر بودن یک صفت را بین افراد سنجید.
مقیاسهای نسبی
مقیاسهای نسبی (Ratio Scale) را میتوان در واقع گونهای از مقیاسهای فاصلهای دانست. تنها تفاوت آن با مقیاس فاصلهای این است که مقیاس نسبی دارای نقطه صفر واقعی میباشد. مبدأ سنجش، یک مبدأ واقعی یا به اصطلاح معمول «صفر مطلق» است؛ برای مثال در سنجش جمعیت یک روستا و یا سن و درآمد افراد، مبدأ سنجش صفر واقعی خواهد بود.
آمار مهندسی
آمار مهندسی یکی از شاخههای نوین دانش آمار ریاضی میباشد که مباحث آن بیشتر برای امور کاربردی و عملی پیش بینی شدهاست. آمار مهندسی شامل مباحث متغیرهای تصادفی، احتمالات و پیشامدهای تصادفی و آزمون فرض میباشد.
احتمالات
بطور ساده، احتمالات (به انگلیسی: Probability) به شانس وقوع یک حادثه گفته میشود.
احتمال معمولاً مورد استفاده برای توصیف نگرش ذهن نسبت به گزاره هایی است که ما از حقیقت انها مطمئن نیستیم. گزاره های مورد نظر معمولاً از فرم "آیا یک رویداد خاص رخ می دهد؟" و نگرش ذهن ما از فرم "چقدر اطمینان داریم که این رویداد رخ خواهد داد؟" است. میزان اطمینان ما، قابل توصیف به صورت عددی می باشد که این عدد مقداری بین 0 و 1 را گرفته و آن را احتمال می نا میم. هر چه احتمال یک رویداد بیشتر باشد، ما مطمئن تر خواهیم بود که آن رویداد رخ خواهد داد. درواقع میزان اطمینان ما از اینکه یک واقعه (تصادفی) اتفاق خواهد افتاد.
نظریهٔ احتمالات
نظریهٔ احتمالات به شاخهای از ریاضیات گویند که با تحلیل وقایع تصادفی سروکار دارد.
مانند دیگر نظریه ها، نظریه احتمال نمایشی از مفاهیم احتمال به صورت شرایط صوری (فرمولی) است – شرایطی که میتواند به طور جدا از معنای خود در نظر گرفته شود. این فرمولبندی صوری توسط قوانین ریاضی و منطق دستکاری، ونتیجه های حاصله، تفسیر و یا دوباره به دامنه مسئله ترجمه می شوند.
حداقل دو تلاش موفق برای به بصورت فرمول دراوردن احتمال وجود دار : فرمولاسیون کولموگروف و فرمولاسیون کاکس. در فرمولاسیون کولموگروف (نگاه کنیدبه )، مجموعه ها به عنوان واقعه و احتمالات را به عنوان میزانی روی یک سری از مجموعه ها تفسیرمی کنند. در نظریه کاکس، احتمال به عنوان یک اصل (که هست، بدون تجزیه و تحلیل بیشتر) و تاکید بر روی ساخت یک انتساب سازگار از مقادیر احتمال برای گزاره ها است. در هر دو مورد، قوانین احتمال یکی هستند مگر برای جزئیات تکنیکی مربوط به آنها.
روشهای دیگری نیز برای کمی کردن میزان عدم قطعیت، مانند نظریه Dempster-Shafer theory یا possibility theory وجود دارد ، اما آن ها به طور اساسی با آنچه گفته شد، تفاوت دارند و با درک معمول از قوانین احتمال سازگار نیستند.
تاریخچه
مطالعه علمی احتمال، توسعه ای مدرن است. قمارنشان می دهد که علاقه به ایده های تعیین کمیت برای احتمالات به هزاران سال می رسد، اما توصیفات دقیق ریاضی خیلی دیرتر به وجود آمد. دلایلی البته وجود دارد که توسعه ریاضیات احتمالات را کند می کند. در حالی که بازی های شانس انگیزه ای برای مطالعه ریاضی احتمال بودند، اما مسائل اساسی هنوز هم تحت تاثیر خرافات قماربازان پوشیده می شود.
به گفته ریچارد جفری، "قبل از اواسط قرن هفدهم، اصطلاح ‘’ احتمالی’’ به معنای قابل تایید (تصویب) و در آن معنا چه برای عقیده افراد و چه برای عمل مورد استفاده بود. در واقع افکار یا اقدام احتمالی، رفتاری بود که مردم معقول درآن شرایط از خود نشان می دادند." البته به خصوص در زمینه های قانونی ،احتمالی (به انگلیسی: Probability) همچنین می تواند به گزاره ای که شواهد خوبی برای اثبات آن وجود دارد، اطلاق شود.
گذشته از کار ابتدایی توسط Girolamo Cardano در قرن 16 اصول احتمالات به مکاتبات پیر دو فرما و بلز پاسکال (1654). کریستین هویگنس (1657) اولین مدل شناخته شده علمی از این موضوع را داد. یاکوب برنولی ARS Conjectandi (منتشرشده پس ازمرگ،1713) و اصول شانس Abraham de Moivre (1718) این موضوع را به عنوان شاخه ای از ریاضیات مطرح می کند. برای تاریخچه ای از توسعه های اولیه مفهوم احتمال ریاضی، ظهور احتمال هک ایان و علم حدس جیمز فرانکلین را ببینید.
تئوری خطاها ممکن است از Roger Cotes's Opera Miscellanea (منتشرشده پس ازمرگ،1722) سرچشمه گرفته باشد، اما شرح حالی که توماس سیمپسون در سال 1755 آماده کرد(چاپ 1756)، برای اولین بار اعمال این نظریه به بحث در مورد خطاهای مشاهده است. چاپ مجدد (1757) این شرح حال نشان می دهد که خطاهای مثبت و منفی هر دو به یک اندازه قابل پیشبینی هستند، و با اختصاص برخی از محدودیت های معین، بازه ای برای تمام خطاها ارائه می دهد.سیمپسون همچنین در مورد خطاهای پیوسته بحث می کند و یک منحنی احتمال را توصیف می کند.
پیر سیمون لاپلاس(1774) برای اولین بار سعی دراستنتاج قانونی برای توصیف مشاهدات از نظر اصول تئوری احتمالات کرد. او قانون احتمال خطاها را با یک منحنی به صورت y = \phi(x), x ، x هر نوع خطا و y احتمال آن معرفی می کند و 3 خاصیت برای این منحنی وضع می کند:
نسبت به محور y متقارن است
محور x مجانب است، احتمال خطا در \infty صفر است
مساحت زیر نمودار آن برابر 1 است.
او همچنین، در سال 1781، یک فرمول برای قانون امکان خطا ( اصطلاحی که لاگرانژ سال 1774 مورد استفاده قرار داد) ارائه کرد، اما به معادلات منظمی منجر نشد.
به طور کلی پیدایش فنون و مفاهیم مربوط به احتمالات را باید به آغاز مدلسازی ریاضی و استخراج و اکتشاف دانش در زمینههای پیچیده تر علوم نسبت داد.
تفسیرها و تحلیلهای مفاهیم احتمالات
کلمه احتمال تعریف مفرد مستقیم برای کاربرد عملی ندارد. در واقع، چندین دسته گسترده از تفسیر احتمال، که پیروان دارای دیدگاه های مختلف (و گاهی متضاد) در مورد ماهیت اساسی احتمال وجود دارد.
Frequentists
Subjectivists
Bayesians
کاربردها
نظریه احتمال در زندگی روزمره در ارزیابی ریسک و در تجارت در بازار کالاها اعمال می شود. دولت ها به طور معمول روش های احتمالاتی را در تنظیم محیط زیست اعمال می کنند، که آن را تجزیه و تحلیل مسیر می نامند. یک مثال خوب اثر احتمال هر گونه درگیری گسترده در خاورمیانه بر قیمت نفت است، که اثرات موج واری روی اقتصاد کل جهان می گذارد. ارزیابی که توسط یک معامله گر کالا زمانیکه احتمال جنگ بیشترباشد، در مقابل حالتی که احتمال کمتری دارد، قیمت ها را بالا و پایین می فرستد و معامله گران دیگر را نیز از نظرات خود آگاه می کند. در واقع، احتمالات (در تجارت) به طور مستقل ارزیابی نمیشوند و لزوماً عقلانی نیستند. تئوری های رفتار مالی برای توصیف اثر فکر گروهی در قیمت گذاری ، در سیاست، و در صلح و درگیری ظهور کردند.
می توان گفت که کشف روش های جدی برای سنجش و ترکیب ارزیابی های احتمال، عمیقاً جامعه مدرن را تحت تاثیر قرار داده است. مثلاً اکثر شهروندان اهمیت بیشتری به اینکه چگونه ارزیابی های احتمال وشانس ساخته می شوند، می دهند واینکه تاثیر آنها در تصمیم گیری ها بزرگتر و به ویژه در دموکراسی چگونه است.
یکی دیگر از کاربردهای قابل توجه نظریه احتمال در زندگی روزمره، قابلیت اطمینان می باشد. بسیاری از محصولات مصرفی، از جمله خودروها و لوازم الکترونیکی مصرفی، در طراحی خود به منظور کاهش احتمال خرابی(شکست) از نظریه قابلیت اطمینان استفاده می کنند. تولید کننده با توجه به احتمال خرابی یک محصول، آنرا گارانتی می کند.
علوم اجتماعی
نقش پایه و اساس را برای بیشتر علوم اجتماعی داراست. آزمونهای آماری فواصل اطمینان شیوههای رگرسیون (پس رفت)
نظریه احتمالات
نظریهٔ احتمالات مطالعهٔ رویدادهای احتمالی از دیدگاه ریاضیات است. بعبارت دیگر، نظریه احتمالات به شاخهای از ریاضیات گویند که با تحلیل وقایع تصادفی سروکار دارد. هسته تئوری احتمالات را متغیرهای تصادفی و فرآیندهای تصادفی و پیشامدها تشکیل میدهند. تئوری احتمالات علاوه بر توضیح پدیدههای تصادفی به بررسی پدیدههایی میپردازد که لزوما تصادفی نیستند ولی با تکرار زیاد دفعات آزمایش نتایج از الگویی مشخص پیروی میکنند، مثلاً در آزمایش پرتاب سکه یا تاس با تکرار آزمایش میتوانیم احتمال وقوع پدیدههای مختلف را حدس بزنیم و مورد بررسی قرار دهیم. نتیجه بررسی این الگوها قانون اعداد بزرگ و قضیه حد مرکزی است.
پیشینه
نخستین کتابها را دو دانشمند ایتالیایی درباره بازی با تاس نوشتند: جه رولاموکاردان و گالیلئو گالیله. بااین همه باید آغاز بحث دقیق درباره احتمال را سده هفدهم و با کارهای بلز پاسکال و پییر فرما، ریاضیدانان فرانسوی و کریستین هویگنس هلندی دانست. پاسکال و فرما کتابی در این باره ننوشتند و تنها در نامههای خود به دیگران درباره کاربرد آنالیز ترکیبی در مسالههای مربوط به شانس صحبت کردهاند، ولی هویگنس کتابی با نام بازی با تاس نوشت که اگر چه با کتاب کاردان هم نام است ولی از نظر تحلیل علمی در سطح بسیار بالاتری است. کار آنان توسط یاکوب برنولی و دموآور در قرن هجدهم میلادی ادامه یافت، برنولی کتاب روش حدس زدن را نوشت و قانون عددهای بزرگ را کشف کرد. مساله معروف سوزن نیز در اواسط همین قرن توسط کنت دو بوفون مطرح و حل شد. در سده هجدهم و ابتدای سده نوزدهم نظریه احتمال در دانشهای طبیعی و صنعت به طور جدی کاربرد پیدا کرد. در این دوره نخستین قضیههای نظریه احتمال یعنی قضایای لاپلاس، پواسون، لژاندر و گاوس ثابت شد. در نیمه دوم سده نوزدهم دانشمندان روسی تاثیر زیادی در پیشرفت نظریه احتمال داشتند، چبیشف و شاگردانش، لیاپونوف و مارکوف یک رشته از مسالههای کلی نظریه احتمال را حل کردند و قضایای برنولی و لاپلاس را تعمیم دادند. در آغاز قرن بیستم متخصصان کارهای قبلی را منظم نموده و ساختمان اصول موضوعه احتمال را بنا نمودند. در این دوره دانشمندان زیادی روی نظریه احتمال کار کردند: در فرانسه، بورل، لهوی و فرهشه؛ در آلمان، میزس؛ در آمریکا، وینر، فه لر و دوب؛ در سوئد، کرامر؛ در شوروی، خین چین، سلوتسکی، رومانوسکی، سمپرنوف، گنه دنکو اما درخشانترین نام در این عرصه کولموگروف روسی است که اصول موضوع احتمال را در کتابی به نام مبانی تئوری احتمال در آلمان منتشر کرد.
مفهوم
مفهوم احتمال در مورد ارتباط یا پیوند دو متغیر به کار میرود، به این معنی که ارتباط یا پیوند آنها به صورتی است که حضور، شکل، وسعت و اهمیت هر یک وابسته به حضور، شکل، و اهمیت دیگری است. این مفهوم به صورت محدودتر و در مورد ارتباط دو متغیر کمّی نیز بهکار برده میشود.
آزمایش تصادفی
به آزمایشی گفته میشود که نتیجه آن قبل از انجام آزمایش مشخص نیست و بتوان آن آزمایش را در شرایط یکسان و به دفعات دلخواه انجام داد.
فضای نمونه
به مجموعهای از تمام نتایج ممکن در یک آزمایش تصادفی فضای نمونه میگویند.
کاربرد احتمال در زندگی
یک تأثیر مهم نظریه احتمال در زندگی روزمره در ارزیابی ریسک پذیری و در تجارت در مورد خرید و فروش اجناس میباشد. حکومتها به طور خاص روشهای احتمال را در تنظیم جوامع اعمال میکنند که به عنوان «آنالیز خط مشی» نامیده میشود و غالباً سطح رفاه را با استفاده از متدهایی که در طبیعت تصادفی اند اندازه میگیرند و برنامههایی را انتخاب میکنند تا اثر احتمال آنها را روی جمعیت به صورت کلی از نظر آماری ارزیابی کنند. این گفته صحیح نیست که آمار، خود در مدل سازی درگیر هست زیرا که ارزیابیهای میزان ریسک وابسته به زمان هستند و بنابراین مستلزم مـدلهای احتمال قوی تر هستند؛ مثلاً «احتمال۹/۱۱ دیگری»؛ قانون اعداد کوچک در جنین مواردی اعمال میشود و برداشت اثر چنین انتخابهایی است که روشهای آماری را به صورت یک موضوع سیاسی در میآورد.
یک مثال خوب اثر احتمال قلمداد شده از مجادلات خاورمیانه بر روی قیمت نفت است که دارای اثرات متلاطمی از لحظ آماری روی اقتصاد کلی دارد. یک ارزیابی توسط یک واحد تجاری در مورد این که احتمال وقوع یک جنگ زیاد است یا کم باعث نوسان قیمتها میشود و سایر تجار را برای انجام کار مشابه تشویق میکند. مطابق با این اصل، احتمالات به طور مستقل ارزیابی نمیشوند و ضرورتاً به طور منطقی برخورد صورت نمیگیرد. نظریه اعتبارات رفتاری، به وجود آمدهاست تا اثر این تفکرات گروهی را روی قیمتها، سیاستها و روی صلح و مجادله توضیح دهد.
به طور استدلالی میتوان گفت که کشف روشهای جدی برای ارزیابی و ترکیب ارزیابیهای احتمالی دارای اثر شدیدی روی جامعه مدرن داشتهاست. یک مثال خوب کاربرد نظریه بازیها که به طور بنیادین بر پایه احتمال ریخته شدهاست در مورد جنگ سرد و دکترین انهدام با اطمینان بخشی متقابل است. مشابهاً ممکن است برای اغلب شهروندان دارای اهمیت باشد که بفهمند چگونه بختها و ارزیابیهای احتمال صورت میگیرد و چگونه آنها میتوانند در تصمیم گیریها به ویژه در زمینه دموکراسی دخالت کنند.
کاربرد مهم دیگر نظریه احتمال در زندگی روزمره، اعتبار است. اغلب تولیدات مصرفی مثل اتومبیل و وسایل الکترونیکی در طراحی آنها از نظریه اعتبار استفاده میشود به نحوی که احتمال نقص آنها کاهش یابد. احتمال نقص با مدت ضمانت فرآورده معمولاً ارتباط نزدیک دارد.
نقد ها
تصمیم گیری یا عدم تصمیم گیری
یکی از نقد هایی که به نظریه ی احتمال وارد است، مبتنی بودن آن بر فراوانی نسبی یک پیشامد به عنوان احتمال رخداد آن است. به دیگر بیان، نظریه احتمال، احتمال رخداد یک پیشامد را معادل با ایمان ما نسبت به رخداد آن پدیده می داند و ایمان به نسبت به رخداد آن پیشامد را معادل فراوانی نسبی آن پدیده در یک آزمایش آماری میداند.. در این اعتقاد دو ایراد فلسفی وجود دارد: اولا: ایمان ما نسبت به رخداد یک پیشامد برابر با احتمال رخداد پیشامد در نظر گرفته شده است. این به این معناست که ایمان درونی انسان به رخداد یک پیشامد برابر با احتمال حقیقتی است که در بیرون رخ خواهد داد. که این تطابق، فاقد هر گونه توجیه منطقی است. ثانیا: احتمال رخداد را برابر با فراوانی نسبی آن پیشامد در آزمایش آماری در نظر می گیرد که این نیز محل بحث است. به عنوان مثال فرض کنید که شما در بازی قماری شرکت کرده اید که با محاسبه ی احتمال ها بر اساس تئوری موجود، احتمال پیروزی شما 2/3 است. لذا سرمایه گذاری در این قمار در 2/3 اوقات به نفع شماست. فرض کنید که بازی 15 دور است. در این صورت شما باید 10 دور این بازی را احتمالا پیروز شوید. شما بازی را شروع می کنید و تا دور 11_ام شکست می خورید و و دور 12 را می برید و دور 13 و 14 را شکست می خورید و دور 15_ام را می برید. این اتفاق یک اتفاق کاملا "ممکن" است. در این صورت شما 0.36- = 13/15 - 1/2 واحد از سرمایه ی خود را از دست داده اید. توجیهی که احتمال دان ها می آورند این است: "اگر تعداد دور ها به بی نهایت میل می کرد شما در 2/3 حالات برنده بودید." در صورتی که در جهان واقعی هیچ گاه بازی هایی با تعداد دور بی نهایت وجود ندارد." در تصمیم گیری های اجتماعی و سیاسی نیز همین امر برقرار است. ریسک سرمایه گزاری بر اساس این نظریه در نظر گرفتنی است. اما این مساله و شبیه این مساله ها با "نظریه امکان" با دیدگاهی کاملا منطقی قابل بررسی، تحلیل و تصمیم گیری است.
عدم وجود تصادف
باور به تئوری احتمال در تمامی ابعاد مستلزم باور به تصادف است. در حالی که هنوز بشر هیچ پدیده ی تصادفی را اطراف خود ندیده است!!! آن فرآیند هایی که موسوم به فرایند تصادفی هستند به سه دسته عمده تقسیم می شوند:
1- فرآیند هایی که از حیث پیچیدگی مقرون به صرفه ترند که با آنها با دیدگاه تصادفی نگاه کرد. مانند جدا شدن اتم های کربن در فضای آزاد. یا پیشامد فرو ریختن پل در حالتی که بار روی پل استاتیکی می شود.
2- فرآیند هایی که تصادفی بودن آنها صرفا به علت عدم علم و عدم توانایی دسترسی ما به علت دقیق آن پیشامدها است. مانند اصل عدم قطعیت هایزنبرگ
3- فرآیند هایی که تصادفی بودن آنها به علت وجود اراده ی یک موجود مختار است. مانند پرتاب یک سکه. و یا اکثر فرایند های اجتماعی و انسانی.
درصورتی که در هر سه حالت بالا با شرط آگاهی ما از مکانیزم دقیق پیشامد، پسوند "تصادفی" خود به خود حذف می شود. اگر بدانیم که تمام نیرو هایی که بر پل وارد می شوند به چه صورت است، اگر "ببینیم" که حرکت دقیق ذرات بنیادین به چه صورت است، اگر مکانیک پرتاب یک سکه را در هر تعداد مرتبه ی دلخواه به ازای هر مقدار نیرو که پرتاب کننده اراده می کند، فرموله کنیم و قص علی هذا، هیچ فرایند تصادفی وجود نخواهد داشت. چه برسد که این تصادف فرموله شود و بر مبنای نتایج محاسبات آنها، تصمیم گیری شود.
اعداد تصادفی
اعداد تصادفی در ریاضی، عبارتند از خروجیهایی که از پیش تعیین نشدهاند. این دسته اعداد برای امتحان شانس و همچنین برای امتحان حاصل کردن برنامهها به کار میروند. انسانها قابلیت محاسبه اعداد تصادفی را ندارند.
کاربرد در محاسبات
برای به دست آوردن مقادیر تصادفی در ماشین حسابها و برنامه نویسی از متد تایمر استفاده میشود. برای مثال، اکس ثانیه، عدد(۷.)۹ را در خروجی نمایش میدهد، که میتواند به صورت زیر نوشته شود:(زبان برنامه: Visual Basic ۶)
Dim rNum as Long
MyRN.Caption = Rnd(rNum) * 10
هر بار برنامه اجرا میگردد، تایمر از صفر شروع میشود و یک سری اعداد نمایان هر دفعه تکرار میشوند. برای جلوگیری از تکرار این حلقهها، معمولاً از دستور Randomize استفاده میگردد. در این حالت، در هر اجرا اعداد متفاوتی خواهیم داشت:
Dim rNum as Long
Randomize
MyRN.Caption = Rnd(rNum) * 10
درکنار این مبحث، حروف تصادفی نیز وجود دارند. آنها شامل حروف بزرگ ویا کوچک میشوند. حروف غیر استاندارد هم در این مجموعه قرار میگیرند.
توان آماری
توان یک آزمون آماری احتمال رد کردن فرض صفر اشتباه میباشد (احتمال آنکه تست آماری مرتکب خطای نوع دوم نشود). هر چه توان یک تست بیشتر باشد احتمال وقوع خطای نوع دوم کمتر خواهد بود.
محققان همیشه نگران این بوده اند که نکند فرضیه صفر را رد کنند در حالی که در واقع درست بوده است (تست آماری مرتکب خطای نوع یک شود) یا اینکه نتوانند فرضیه صفر را رد کنند در حالی که این روش های استفاده شده بوده اند که اثری واقعی داشتهاند (تست آماری مرتکب خطای نوع دو شود). توان آماری یک تست، احتمال آن است که منجر به این میشود که شما فرضیه صفر را رد کنید وقتی فرضیه در واقع غلط است. چون بیشتر تست های امری در شرایطی انجام میشوند که عامل اصلی(treatment)، حداقل کمی اثر روی نتیجه دارد، توان آماری به صورت احتمال اینکه آن تست "منجر به نتیجه گیری درستی در مورد فرضیه صفر میشود"، تعبیر میشود.
توان یک تست آماری عبارت است از: یک، منهای احتمال ایجاد خطای نوع دو. یا به عبارتی، احتمال اینکه شما از خطای نوع دو دوری میکنید.
در مطالعات با توان آماری بالا، خیلی کم پیش میاید که در تشخیص اثرات تمرین اشتباه کنند.
توان یک تست آماری، شامل عملکردِ: حساسیت، اندازه اثر در جمیعت آماری، و استاندارد های استفاده شده برای اندازه گیری فرضیه آماری است. - ساده ترین راه برای افزایش حساسیت یک تحقیق، افزایش تعداد آزمودنی هاست. - در مورد استاندارد، ساده تر آن است که فرضیه صفر را رد کنیم اگر سطح معناداری، ۰.۰۵ باشد تا ۰.۰۱ یا ۰.۰۰۱.
سه قدم برای تعین توان آماری: ۱- مشخص کردن حد، برای معنی دار بودن آماری. فرضیه چیست؟ سطح معناداری چقدر است؟
۲- حدس زدن اندازه اثر. انتظار دارد که درمان(treatment)، دارای اثری کم، زیاد، یا متوسط باشد؟
توزیع احتمال
در نظریه احتمال و آمار تابع توزیع احتمال بیانگر احتمال هر یک از مقادیر متغیر تصادفی (در مورد متغیر گسسته) و یا احتمال قرار گرفتن متغیر در یک بازه مشخص (در مورد متغیر تصادفی پیوسته) میباشد. توزیع تجمعی احتمال یک متغیر تصادفی تابعی است از دامنهٔ آن متغیر بر بازهٔ 0,1. به طوری که احتمال رخدادن پیشامدهای با مقدار عددی کمتر از آن را نمایش میدهد.
توزیع احتمالی گسسته
در آمار و احتمالات، به دستهای از توزیعها توزیع گسسته گویند که در آنها متغیر تصادفی تنها میتواند تعداد محدود و یا تعداد شمارایی از مقادیر را اختیار کند.
تولید اعداد تصادفی
یک تولیدکننده اعداد تصادفی (به انگلیسی: Random Number Generation، بهاختصار:RNG) وسیلهای فیزیکی و یا روشی محاسباتی است که برای تولید دنبالهای از اعداد که الگوی خاصی ندارند (یعنی بطور تصادفی ظاهر شدهاند) به کار میرود.
سامانههای رایانهای بطور گسترده برای تولید اعداد تصادفی مورد استفاده قرار میگیرند در حالیکه تولید کنندههای خوبی نیستند هرچند الگوهای آنها به راحتی قابل تشخیص نیست.
از زمانهای قدیم روشهایی برای تولید این اعداد وجود داشتهاست از جمله پرتاب تاس، پرتاب سکه و برهم زدن کارتها که همچنان در بازیها و قمارخانهها مورداستفاده قرار میگیرند. در واقع کاربرد بسیار این اعداد موجب گوناگونی و فراوانی روشهای تولید این اعداد (از لحاظ مدت زمانی که برای تولید این اعداد سپری میشود و الگوهای مورد استفاده آنها) شدهاست.
روشهای فیزیکی
برخی از پدیدههای طبیعی الگوهای مناسبی برای تولید این اعداد هستند به عنوان مثال برخی پدیدههای فیزیکی از جمله اختلالات حرارتی در دیودهای زنر (Zener Diodes) دارای رفتاری کاملاً تصادفی هستند و میتوانند پایهای برای تولید RNGهای فیزیکی و سختافزاری باشند.
همانطور که اشاره شد، الگوهای طبیعی جالبی برای تولید اعداد تصادفی وجود دارد؛ یک روش متداول استفاده از یک تابع درهم ساز (که ورودی اش جریانی از فریمهای ویدئوییٍ یک منبع غیر قابل پیش بینی میباشد) است. به عنوان مثال لاواراند (Lavarand)از تصاویر تعدادی لامپ لاوا(Lava Lamps) استفاده کرد. Lithium Technologies از تصاویر آسمان و Random.org از صداهای آشفته جوی استفاده میکند.
روشهای محاسبهای
تولیدکنندههای اعداد شبه تصادفی الگوریتمهایی با قابلیت تولید اعداد تصادفی هستند هرچند اعداد تولید شده توسط آنها به طور تناوبی تکرار میشود و یا آنکه حافظه زیادی را اشغال میکنند.
یک روش ساده که با قلم و کاغذ نیز قابل اجراست روش میانه مربع (Middle Square Method) است که توسط جان فون نیومن (John Von Neumann) ابداع شد که بسیار سادهاست ولی اعداد تولیدی آن از لحاظ آماری کیفیت خوبی ندارند.
بسیاری از زبانهای برنامهنویسی رایانه شامل توابع کتابخانهای هستند که برای تولید اعداد تصادفی (یک بایت، کلمه ویا اعداداعشاری تصادفی با توزیع یکنواخت بین ۰ و ۱)طراحی شدهاند. این توابع کتابخانهای اغلب از لحاظ خصوصیات آماری ضعیف هستند و الگوهایشان پس از تنها ۱۰۰۰ رشته دوباره تکرار میشود، آنها اغلب با زمان واقعی رایانه به عنوان seed راهاندازی میشوند. در واقع این توابع در بعضی موارد به تعداد کافی رویداد تصادفی تولید میکنند (مثلاً در بازیهای ویدئویی) ولی وقتی رویدادهای تصادفی با کیفیت بالا مورد نظر است، ناکارآمد هستند (مثلاً در رمزنگاری).
کاربردهای اعداد تصادفی
شبیهسازی: وقتی یک رایانه برای شبیهسازی مفاهیم طبیعی مورد استفاده قرار میگیرد، اعداد تصادفی برای واقعی نشان دادن اجزا و رویدادها مورد نیاز هستند. شبیهسازی بسیاری از رشته هارا پوشش میدهد مثلاً فیزیک هستهای
نمونهبرداری: آزمودن همه حالات ممکن برای یک سامانه اغلب غیر عملی است اما وضعیت و درستی یک نمونه تصادفی میتواند حالت کلی سیستم را شرح دهد.
آنالیز عددی: روشهای مبتکرانهای برای حل مسائل عددی پیچیده ابداع شدهاست که از اعداد تصادفی استفاده میکنند.
کتابهای بسیاری نیز در همین مورد نوشته شدهاند.
برنامهنویسی رایانهای: مقادیر تصادفی منابع خوبی از اطلاعات برای تست کردن کارایی الگوریتمهای کامپیوتری هستند؛ از همه مهمتر نقش آنها در اجرای الگوریتمهای تصادفی است.
تصمیمگیری: گزارشهایی مبنی براینکه برخی مدیران اجرایی تصمیمات خود را برپایه پرتاب سکه و یا دارت میگیرند؛ در واقع بعضی وقتها باید بدون غرضورزی تصمیمات گرفته شوند.
تولید اعداد تصادفی در رایانه
از آنجاییکه رایانهها ماشینهایی از نوع معیّن (Deterministic) هستند، با دریافت ورودی یکسان، همیشه یک خروجی بیرون میدهند. ازین رو تولید اعداد تصادفی در رایانه مبحثی است
در زبانهای برنامهنویسی گوناگون، تابعی وجود دارد که عددی تصادفی و معمولاً در بازهٔ صفر و یک تولید میکند. این تابع باید به گونهای باشد که با چند بار تولید عدد تصادفی کاربر قادر به حدس زدن و پیدا کردن قاعده و الگویی در ایجاد این اعداد نشود.
هر بار که این تابع صدا زده میشود، رایانه عدد تولید شدهٔ پیشین را به عنوان ورودی جدید تابع تولید عدد تصادفی میفرستد. منشاء مشکل نیز در همین مرحله است.
هر بار که این تابع صدا زده شود، بر اساس ماهیت جبری ماشین و با توجه به مقدار اولیهٔ فرستاده شده به تابع تولید عدد تصادفی (seed) باید با یک دنباله از اعداد مشابه یکدیگر مواجه شویم.
چگونه مقدار اولیه مناسب را پیدا کنیم؟
در برنامهنویسی به عنوان مثال برای نوشتن یک بازی راهحلهای گوناگونی مانند قرار دادن مقدار اولیه برابر با تعداد بازیهای انجام شده بر روی رایانه و یا ذخیرهٔ خروجی آخرین seed از برنامهٔ قبلی در حال اجرا است. با اینحال کماکان مشکل مقدار دهی اولین seed پابرجاست.
اولین مقدار اولیه
راحتترین راه حل این مسأله در دنیای کامپیوتر استفاده از زمان فعلی دستگاه است. کامپیوترهای امروزی زمان را با دقت میلیثانیه در دسترس دارند. برنامهها میتوانند زمان اولین اجرای خود را به عنوان seed به اولین باری که تابع تولید اعداد تصادفی صدا زده میشود، بفرستند. ولی اگر باز هم دونفر به طور کاملاً همزمان برنامه را اجرا کنند خروجی یکسان دریافت خواهند کرد. این مشکل هم با افزودن معیارهای دیگری به seed مانند زمان آخرین کلیک موشی (Mouse Click)، مدت زمان بالا بودن سیستمعامل و مواردی مشابه، به مقدار زیادی کاهش داد. با افزودن این معیارها و معیارهای مشابه دیگر به برنامه احتمال ایجاد تشابه را به سمت صفر کاهش میدهیم.
در همان زبان برنامهنویسی جاوا که به عنوان نمونه آورده شد، ورودی Constructor یک عدد از نوع اولیهٔ long به عنوان ورودی میگیرد. این عدد long یک عدد ۶۴ بیتی در جاوا است که خود باعث محدود شدن seed و امکان به وجود آمدن اعداد تصادفی برابر را فراهم میسازد. بنابر این مشکل کاملاً حل نشدهاست.
روشهای جهتیابی در روز
جهتیابی به کمک موقعیت خورشید در آسمان
۱- خورشید صبح تقریباً از سمت شرق طلوع میکند، و شب تقریباً در سمت غرب غروب میکند.
این مطلب فقط در اول بهار و پاییز صحیح است؛ یعنی در اولین روز بهار و پاییز خورشید دقیقاً از شرق طلوع و در غرب غروب میکند، ولی در زمانهای دیگر، محل طلوع و غروب خورشید نسبت به مشرق و مغرب مقداری انحراف دارد.
در تابستان طلوع و غروب خورشید شمالیتر از شرق و غرب است، و در زمستان جنوبیتر از شرق و غرب میباشد. در اول تابستان و زمستان، محل طلوع و غروب خورشید حداقل حدود ۲۳٫۵ درجه با محل دقیق شرق و غرب فاصله دارد، که این خطا به هیچ وجه قابل چشم پوشی نیست. در واقع از آنجا که موقعیت دقیق خورشید با توجه به فصل و عرض جغرافیایی متغیر است، این روش نسبتاً غیردقیق است.
۲- در نیمکرهٔ شمالی زمین، در زمان ظهر شرعی خورشید همیشه دقیقاً در جهت جنوب است و سایهٔ اجسام رو به شمال میافتد.
ظهر شرعی یا ظهر نجومی، دقیقاً هنگامی است که خورشید به بالاترین نقطه خود در آسمان میرسد. در این زمان، سایهٔ شاخص به حداقل خود در روز میرسد، و پس از آن دوباره افزایش مییابد؛ همان زمان اذان ظهر.
برای دانستن زمان ظهر شرعی میتوان به روزنامهها مراجعه کرد یا منتظر صدای اذان ظهر شد. ظهر شرعی حدوداً نیمه بین طلوع آفتاب و غروب آفتاب است.
۳- حرکت خورشید از شرق به غرب است؛ و این هم میتواند روشی برای یافتن جهتهای جغرافیایی باشد.
جهتیابی با سایهٔ چوب(شاخص)
شاخص، چوب یا میلهای صاف و راست است (مثلاً شاخه نسبتاً صافی از یک درخت به طول مثلاً یک متر) که به طور عمودی در زمینی مسطح و هموار و افقی(تراز و میزان) فرو شدهاست.
روش اول: نوک(انتهای) سایهٔ شاخص روی زمین را [مثلاً با یک سنگ] علامتگذاری میکنیم. مدتی (مثلاً ده-بیست دقیقه بعد، یا بیشتر) صبر میکنیم تا نوک سایه چند سانتیمتر جابهجا شود. حال محل جدید سایهٔ شاخص (که تغییر مکان دادهاست) را علامتگذاری مینماییم. حال اگر این دو نقطه را با خطی به هم وصل کنیم، جهت شرق-غرب را مشخص میکند. نقطهٔ علامتگذاری اول سمت غرب، و نقطهٔ دوم سمت شرق را نشان میدهد. یعنی اگر طوری بایستیم که پای چپمان را روی نقطهٔ اول و پای راستمان را روی نقطهٔ دوم بگذاریم، روبرویمان شمال را نشان میدهد، و رو به خورشید (پشت سرمان) جنوب است.
از آنجا که جهت ظاهری حرکت خورشید در آسمان از شرق به غرب است، جهت حرکت سایهٔ خورشید بر روی زمین از غرب به شرق خواهد بود. یعنی در نیمکره شمالی سایهها ساعتگرد میچرخند.
هر چه از استوا دورتر بشویم، از دقت پاسخ در این روش کاسته میشود. یعنی در مناطق قطبی (عرض جغرافیایی بالاتر از ۶۰ درجه) استفاده از آن توصیه نمیشود.
در شبهای مهتابی هم از این روش میتوان استفاده کرد: به جای خورشید از ماه استفاده کنید.
روش دوم(دقیقتر): محل سایهٔ شاخص را زمانی پیش از ظهر علامت گذاری میکنیم. دایره یا کمانی به مرکز محل شاخص و به شعاع محل علامتگذاری شده میکشیم. سایه به تدریج که به سمت شرق میرود کوتاهتر میشود، در ظهر به کوتاهترین اندازهاش میرسد، و بعداز ظهر به تدریج بلندتر میگردد. هر گاه بعد از ظهر سایهٔ شاخص از روی کمان گذشت (یعنی سایهٔ شاخص هماندازهٔ پیش از ظهرش شد) آنجا را به عنوان نقطهٔ دوم علامتگذاری میکنیم. مانند روش پیشین، این نقطه سمت شرق و نقطهٔ پیشین سمت غرب را نشان میدهد.
در واقع هر دو نقطه سایهٔ همفاصله از شاخص، امتداد شرق-غرب را مشخص میکنند.
با اینکه روش پیشین نسبتاً دقیق است، این روش دقیقتر است؛ البته وقت بیشتری برای آن لازم است.
برای کشیدن کمان مثلاً طنابی(مانند بند کفش، نخ دندان) را انتخاب کنید. یک طرف طناب را به شاخص ببندید، و طرف دیگرش را به یک جسم تیز؛ به شکلی که وقتی طناب را میکشید دقیقاً به محل علامتگذاری شده برسد. نیمدایرهای روی زمین با جسم تیز رسم کنید.
وقتی سایهٔ شاخص به حداقل اندازهٔ خود میرسد(در ظهر شرعی)، این سایه سمت جنوب را نشان میدهد (بالای ۲۳٫۵ درجه).
جهتیابی با ساعت عقربهدار
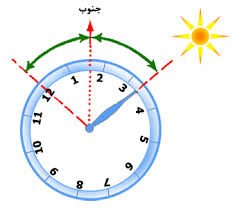
ساعت مچی معمولی (آنالوگ، عقربهای) را به حالت افقی طوری در کف دست نگه میداریم که عقربهٔ ساعتشمار به سمت خورشید اشاره کند. در این حالت، نیمسازِ زاویهای که عقربهٔ ساعتشمار با عدد ۱۲ ساعت میسازد (زاویهٔ کوچکتر، نه بزرگتر)، جهت جنوب را نشان میدهد. یعنی مثلاً اگر چوبکبریتی را [به طور افقی] در نیمهٔ راه میان عقربهٔ ساعتشمار و عدد ۱۲ ساعت قرار دهید، به طور شمالی-جنوبی قرار گرفتهاست.
نکات
این که گفته شد عقربهٔ کوچک ساعت به سمت خورشید اشاره کند، یعنی اینکه اگر شاخصی [مثلاً چوبکبریت] ای که در مرکز ساعت قرار دهیم، سایهاش موازی با عقربهٔ ساعتشمار و در جهت مقابل آن باشد. یا اینکه سایهٔ عقربهٔ ساعتشمار درست در زیر خود عقربه قرار گیرد. یا مثلاً اگر چوبی ده-پانزده سانتیمتری را در زمین بهطور عمودی قرار دهیم، ساعت روی زمین به شکلی قرار گرفته باشد که عقربهٔ ساعتشمارش موازی با سایهٔ چوب باشد.
دلیل اینکه زاویه بین عقربهٔ ساعتشمار و ۱۲ را نصف میکنیم این است که: وقتی خوشید یک بار دور زمین میچرخد، ساعت ما دو دور میچرخد(دو تا ۱۲ ساعت). یعنی گرچه روز ۲۴ ساعت است (و یک دور کامل را در ۲۴ ساعت طی میکند)، ساعتهای ما یک دور کامل را در ۱۲ ساعت طی مینماید. اگر ساعت ۲۴ ساعتهای میداشتید، که دور آن به ۲۴ قسمت مساوی تقسیم شده بود، هر گاه عقربهٔ ساعتشمار را رو به خورشید میگرفتید عدد ۱۲ ساعت همیشه جهت جنوب را نشان میداد.
این روش وقتی سمت صحیح را نشان میدهد، که ساعت مورد نظر درست تنظیم شده باشد. یعنی اگر در بهار و تابستان ساعتها را نسبت به ساعت استاندارد یکساعت جلو میبرند، ما باید آن را تصحیح کنیم(ابتدا ساعتمان را یک ساعت عقب ببریم سپس روش را اِعمال کنیم؛ یا نیمساز عقربهٔ ساعتشمار را [به جای ۱۲] با ۱ حساب کنید). همچنین در همهٔ سطح یک کشور معمولاً ساعت یکسانی وجود دارد، که مثلاً در ایران حدود یک ساعت متغیر است (ایران تقریباً بین دو نصفالنهار قرار دارد؛ لذا ظهر شرعی در شرق و غرب ایران حدوداً یک ساعت فاصله دارد.) ساعت صحیح هر مکان همان ساعتی است که هنگام ظهر شرعی در آن در طول سال، اطراف ساعت ۱۲ ظهر است. در واقع برای تعیین دقیق جهتهای جغرافیایی ساعت باید طوری تنظیم باشد که هنگام ظهر شرعی ساعت ۱۲ را نشان دهد.
روش ساعت مچی تا ۲۴ درجه امکان خطا دارد. برای دقت بیشتر باید از آن در عرض جغرافیایی بین ۴۰ و ۶۰ درجه [شمالی یا جنوبی] استفاده شود؛ هر چند در عرض جغرافیایی ۲۳٫۵ تا ۶۶٫۵ درجه [شمالی یا جنوبی] نتیجهاش قابل قبول است.(البته در نیمکردهٔ جنوبی جهت شمال و جنوب برعکس است.) در واقع هر چه به استوا نزدیکتر شویم، از دقت این روش کاسته میشود. ضمناً هر چه زمان به کار بردن این روش به ظهر شرعی نزدیکتر باشد، نتیجهٔ آن دقیقتر خواهد بود.
اگر مطمئن نیستید کدام طرف شمال است و کدام طرف جنوب، به یاد بیاورید که خورشید از شرق بر میخیزد، در غرب مینشیند، و در ظهر سمت جنوب است.
توجه کنید که اگر این روش را در هنگام ظهر شرعی (یعنی ساعت ۱۲) اجرا کنیم، جهت عقربه ساعتشمار خود به سوی جنوب است. یعنی مانند همان روش «جهتیابی با سمت خورشید»، که گفتیم خورشید در ظهر شرعی به سمت جنوب است.
اگر از ساعت دیجیتال استفاده میکنید، میتوانید ساعت عقربهداری را روی یک کاغذ یا روی زمین بکشید (دور دایرهای از ۱ تا ۱۲ بنویسید، و عقربهٔ ساعتشمار را هم بکشید)، و سپس از روش بالا استفاده کنید.
حتی وقتی هوا آفتابی نیست و خورشید به راحتی دیده نمیشود هم گاه سایهٔ خوشید را میتوان دید. اگر یک چوبکبریت را عمود نگه دارید، سایهٔ آن برعکس جهت خورشید میافتد.
روشهای جهتیابی در شب
جهتیابی با ستارهٔ قطبی
از آنجا که ستارهها به محور ستاره قطبی در آسمان میچرخند، در نیمکرهٔ شمالی زمین ستارهٔ قطبی با تقریب بسیار خوبی (حدود ۰٫۷ درجه خطا) جهت شمال جغرافیایی (و نه شمال مغناطیسی) را نشان میدهد؛ یعنی اگر رو به آن بایستیم، رو به شمال خواهیم بود.
برای یافتن ستارهٔ قطبی روشهای مختلفی وجود دارد:
به وسیلهٔ مجموعه ستارگان «دبّ اکبر»: صورت فلکی دبّ اکبر شامل هفت ستارهاست که به شکل ملاقه قرار گرفتهاند: چهار ستاره آن تشکیل یک ذوزنقه را میدهند، و سه ستارهٔ دیگر مانند یک دنباله در ادامه ذوزنقه قرار گرفتهاند. هر گاه دو ستارهای که لبهٔ بیرونی ملاقه را تشکیل میدهند (دو ستارهٔ قاعده کوچک ذوزنقه؛ لبهٔ پیالهٔ ملاقه؛ محلی که آب از آنجا میریزد) را [با خطی فرضی] به هم وصل کنیم، و پنج برابر فاصله میان دو ستاره، به سمت جلو ادامه دهیم، به ستاره قطبی میرسیم.
به وسیلهٔ مجموعه ستارههای «ذاتالکرسی»: صورت فلکی ذاتالکرسی شامل پنج ستارهاست که به شکل W یا M قرار گرفتهاند. هرگاه (مطابق شکل) ستارهٔ وسط W (رأس زاویهٔ وسطی) را حدود پنج برابرِِ «فاصلهٔ آن نسبت به ستارههای اطراف» به سوی جلو ادامه دهیم، به ستارهٔ قطبی میرسیم.
نکات
صورتهای فلکی ذاتالکرسی و دبّ اکبر نسبت به ستارهٔ قطبی تقریباً روبهروی یکدیگر، و دور ستاره قطبی خلاف جهت عقربههای ساعت میچرخند. اگر یکی از آنها پشت کوه پنهان بود، با دیگری میتوان ستارهٔ قطبی را یافت. فاصلهٔ هر کدام از این دو صورت فلکی تا ستارهٔ قطبی تقریباً برابر است.
اگر برای یافتن ستارهها در آسمان از نقشه ستارهیاب (افلاکنما) استفاده میکنید، بهخاطر داشته باشید که ستارهیابها موقعیت ستارهها را در زمان، تاریخ و موقعیت جغرافیایی (طول و عرض جغرافیایی) خاصی نشان میدهند.
هر چه از استوا به سوی قطب شمال برویم، ستارهٔ قطبی در آسمان بالاتر (در ارتفاع بیشتر) دیده میشود. یعنی ستارهٔ قطبی در استوا (عرض جغرافیایی صفر درجه) تقریباً در افق دیده میشود، و در قطب شمال(عرض جغرافیایی ۹۰ درجه) تقریباً بالای سر (سرسو، سمتالرّأس، رأسالقدم) دیده میشود. بالاتر از عرض جغرافیایی ۷۰ درجه شمالی عملاً نمیتوان با ستارهٔ قطبی شمال را پیدا کرد.
جهتیابی با هلال ماه
اگر به دلیل وجود ابر یا درختان نمیتوانید ستارهها را ببینید، میتوانید از ماه برای جهتیابی استفاده کنید.
ماه به شکل هلال باریکی تولد مییابد، و در نیمههای ماه قمری به قرص کامل تبدیل میشود، و سپس در جهت مقابل هلالی میشود. در نیمهٔ اول ماههای قمری قسمت خارجی ماه (تحدب و کوژی ماه، برآمدگی و برجستگی ماه) مانند پیکانی جهت غرب را نشان میدهد. در نیمهٔ دوم ماههای قمری، تحدب ماه به سمت مشرق است.
اگر خطی از بالای هلال به پایین آن وصل کنیم و ادامه دهیم، در نیمهٔ اول ماه قمری شکل p و در نیمهٔ دوم شکل q خواهد داشت.
کره ماه در نیمهٔ اول ماههای قمری پیش از غروب آفتاب طلوع میکند، و در نیمهٔ دوم پس از غروب، تا پایان ماه که پس از نیمهشب طلوع مینماید.
پیدا کردن جنوب توسط ماه: اگر خطی فرضی میان دو نوک تیز هلال ماه رسم کرده و آن را تا زمین ادامه دهید، تقاطع امتداد این خط با افق، نقطه جنوب را [در نیمکرهٔ شمالی زمین] نشان میدهد.
این روش جهتیابی چندان دقیق نیست، ولی حداقل راهنمایی تقریبی را فراهم میسازد. در زمان قرص کامل نمیتوان از این روش استفاده کرد. وقتی ماه به صورت قرص کامل است، میتوان به کمک حرکت ظاهری ماه (که از مشرق به طرف مغرب است) جهتیابی کرد.
روشهای دیگر جهتیابی در شب
حرکت ظاهری ماه در آسمان از شرق به غرب است.
خوشه پروین: دستهای (حدود ده تا پانزده) ستاره، به شکل خوشه انگور، در یک جا مجتمع هستند که به آن مجموعه خوشه پروین میگویند. این ستارگان مانند خورشید از شرق به طرف غرب در حرکتند، ولی در همه حال دُمِ آنها به طرف مشرق است.
ستارگان بادبادکی: حدود هفت -هشت ستاره در آسمان وجود دارد که به شکل بادبادک یا علامت سوال میباشند. این ستارگان نیز از شرق به غرب حرکت میکنند، و در همه حال دنباله بادبادکی آنها بهطرف جنوب است.
کهکشان راه شیری تودهٔ عظیمی از انبوه ستارگان است که تقریباً از شمال شرقی به جنوب غربی امتداد یافتهاست. در شمال شرقی این راه باریک است، و هر چه به سمت جنوب غربی میرود، پهنتر میشود. هر چه به آخر شب نزدیکتر میشویم، قسمت پهن راه شیری به طرف مغرب منحرف میشود.
روشهای جهتیابی، قابل استفاده در روز و شب
جهتیابی با قبله
اگر جهت قبله و میزان انحراف آن از جنوب (یا دیگر جهتهای اصلی) را بدانیم، میتوانیم شمال را تشخیص دهیم. مثلاً اگر در تهران ۳۷ درجه از جنوب سمت به غرب متمایل شویم (یعنی حدوداً جنوب غربی)، به طرف قبله ایستادهایم. پس هرگاه در تهران جهت قبله را بدانیم، اگر ۳۷ درجه از سمت قبله در جهت عکس عقربههای ساعت بچرخیم، به طرف جنوب ایستادهایم، و اگر ۱۴۳ درجه (۳۷-۱۸۰) در جهت عقربههای ساعت بچرخیم، به طرف شمال ایستادهایم.
قبله را از راههای مختلفی میتوان یافت:
قبلهنما: دقیقترین روش تعیین قبله، بهوسیلهٔ قبلهنماست، که آن هم با یک قطبنما انجام میگیرد؛ و اگر ما قطبنما داشته باشیم، با آن قطب را مشخص میکنیم!
محراب مسجد: محراب مساجد به طرف قبلهاست. در نمازخانهها هم معمولاً جهت قبله مشخص شدهاست.
قبرستان: مرده را در قبر روی دست راست، به سمت قبله میخوابانند. پس اگر شما طوری ایستاده باشید که نوشتههای سنگ قبر را به درستی میخوانید، سمت چپتان قبلهاست.
دستشویی: از آنجا که قضای حاجت رو به قبله نباید باشد، معمولاً توالتها را عمود بر قبله میسازند.
جهتیابی با قطبنمای دستساز
اگر قطبنمایی به همراه نداشتید، ولی اتفاقاً یک سوزن یا میخ کوچک در جیبتان یافتید، این روش کمککار شما در ساخت یک قطبنما خواهد بود. البته احتمال استفاده از آن در شرایط واقعی کم است، ولی انجام آن کاری سرگرمکنندهاست.
با مالش دادن یک سوزن فقط در یک جهت به آهنربا -یا حتی احتمالاً چاقوی خودتان-، یا مالیدن آن فقط در یک جهت به پارچهٔ ابریشمی یا پنبهای، سوزنْ مغناطیسی یا قطبی میشود؛ مانند سوزن قطبنما. (مثلاً با ۳۰ بار مالش دادن سوزن به آهنربا از طرف خودتان به سمت بیرون، سوزن به اندازهٔ کافی خاصیت آهنربایی پیدا میکند. همچنین مالش سر سوزن از پایین به بالا بر پارچهٔ ابریشمی باعث میشود که سر سوزن نقطه شمال را نشان دهد). حتی میتوانید آنرا در یک جهت میان موهای سر خود بکشید. توجه کنید که همیشه فقط در یک جهت مالش دهید.
حال اگر آنرا روی یک چوبپنبه یا پوشال کوچک قرار دهید(سوزن را به چوبپنبه چسب بزنید، یا درون آن فرو کنید؛ یا در دو طرف سوزن چوبپنبههایی کوچک فرو کنید)، و روی آب (آب راکد یا ظرفی پر از آب) شناور نمایید، مانند یک قطبنما عمل میکند، و سر سوزن رو به شمال میچرخد. برای اینکه سمت شمال و جنوب سوزن را اشتباه نکنید، این نکته را در نظر بگیرید که -در نیمکرهٔ شمالی زمین- آن سمت قطبنما که تقریباً رو به خورشید و ماه است، سمت جنوب است، زیرا آنها در قسمت جنوبی آسمان قرار دارند. همچنین میتوانید سوزن را با یک آهنربا امتحان کنید، و سپس سمت شمال را با علامتی روی آن مشخص نمایید.
روش دیگر ساخت آهنربا این است که یک میله یا سوزن آهنی یا فولادی را در جهت میدان مغناطیسی زمین تراز کنیم، و سپس آنرا حرارت داده یا بر آن ضربه وارد کنیم. حال اگر این آهنربا را روی سطحی با اصطکاک کم قرار دهیم (روی یک تکه چوب کوچک در آب شناور سازید، یا مثلاً سوزن را با یک ریسمان غیرفلزی آویزان(معلق) نمایید) قطبنمای ما کار میکند؛ یعنی میله آنقدر میچرخد تا در راستای میدان مغناطیسی زمین (شمالی-جنوبی) قرار گیرد.
مغناطیسی کردن سوزن با باتری: اگر سیمی را دور سوزن بپیچانید و برای چند دقیقه سر سیم را به ته باتری وصل کنید، سوزن مغناطیسی میشود.
به دلیل کشش سطحی آب، میتوان سوزن را به تنهایی روی سطح آن شناور کرد. مثلاً میتوان سوزن را روی کاغذی گذاشت، و کاغذ را روی آب گذاشت. اگر کاغذ روی آب بماند که بهتر، و اگر کاغذ در آب فرو برود احتمالاً سوزن روی آب باقی میماند. اگر سوزن را با گریس یا روغنی غیرقابلحل در آب چرب کنید (مثلاً با مالش سوزن به موهای خود سوزن را چرب نمایید)، کار آسانتر خواهد شد. چرب بودن سوزن سبب میشود که سوزن روی سطح آب شناور بماند.
جهتیابی به کمک موقعیت خورشید در آسمان
۱- خورشید صبح تقریباً از سمت شرق طلوع میکند، و شب تقریباً در سمت غرب غروب میکند.
این مطلب فقط در اول بهار و پاییز صحیح است؛ یعنی در اولین روز بهار و پاییز خورشید دقیقاً از شرق طلوع و در غرب غروب میکند، ولی در زمانهای دیگر، محل طلوع و غروب خورشید نسبت به مشرق و مغرب مقداری انحراف دارد.
در تابستان طلوع و غروب خورشید شمالیتر از شرق و غرب است، و در زمستان جنوبیتر از شرق و غرب میباشد. در اول تابستان و زمستان، محل طلوع و غروب خورشید حداقل حدود ۲۳٫۵ درجه با محل دقیق شرق و غرب فاصله دارد، که این خطا به هیچ وجه قابل چشم پوشی نیست. در واقع از آنجا که موقعیت دقیق خورشید با توجه به فصل و عرض جغرافیایی متغیر است، این روش نسبتاً غیردقیق است.
۲- در نیمکرهٔ شمالی زمین، در زمان ظهر شرعی خورشید همیشه دقیقاً در جهت جنوب است و سایهٔ اجسام رو به شمال میافتد.
ظهر شرعی یا ظهر نجومی، دقیقاً هنگامی است که خورشید به بالاترین نقطه خود در آسمان میرسد. در این زمان، سایهٔ شاخص به حداقل خود در روز میرسد، و پس از آن دوباره افزایش مییابد؛ همان زمان اذان ظهر.
برای دانستن زمان ظهر شرعی میتوان به روزنامهها مراجعه کرد یا منتظر صدای اذان ظهر شد. ظهر شرعی حدوداً نیمه بین طلوع آفتاب و غروب آفتاب است.
۳- حرکت خورشید از شرق به غرب است؛ و این هم میتواند روشی برای یافتن جهتهای جغرافیایی باشد.
جهتیابی با سایهٔ چوب(شاخص)
شاخص، چوب یا میلهای صاف و راست است (مثلاً شاخه نسبتاً صافی از یک درخت به طول مثلاً یک متر) که به طور عمودی در زمینی مسطح و هموار و افقی(تراز و میزان) فرو شدهاست.
روش اول: نوک(انتهای) سایهٔ شاخص روی زمین را [مثلاً با یک سنگ] علامتگذاری میکنیم. مدتی (مثلاً ده-بیست دقیقه بعد، یا بیشتر) صبر میکنیم تا نوک سایه چند سانتیمتر جابهجا شود. حال محل جدید سایهٔ شاخص (که تغییر مکان دادهاست) را علامتگذاری مینماییم. حال اگر این دو نقطه را با خطی به هم وصل کنیم، جهت شرق-غرب را مشخص میکند. نقطهٔ علامتگذاری اول سمت غرب، و نقطهٔ دوم سمت شرق را نشان میدهد. یعنی اگر طوری بایستیم که پای چپمان را روی نقطهٔ اول و پای راستمان را روی نقطهٔ دوم بگذاریم، روبرویمان شمال را نشان میدهد، و رو به خورشید (پشت سرمان) جنوب است.
از آنجا که جهت ظاهری حرکت خورشید در آسمان از شرق به غرب است، جهت حرکت سایهٔ خورشید بر روی زمین از غرب به شرق خواهد بود. یعنی در نیمکره شمالی سایهها ساعتگرد میچرخند.
هر چه از استوا دورتر بشویم، از دقت پاسخ در این روش کاسته میشود. یعنی در مناطق قطبی (عرض جغرافیایی بالاتر از ۶۰ درجه) استفاده از آن توصیه نمیشود.
در شبهای مهتابی هم از این روش میتوان استفاده کرد: به جای خورشید از ماه استفاده کنید.
روش دوم(دقیقتر): محل سایهٔ شاخص را زمانی پیش از ظهر علامت گذاری میکنیم. دایره یا کمانی به مرکز محل شاخص و به شعاع محل علامتگذاری شده میکشیم. سایه به تدریج که به سمت شرق میرود کوتاهتر میشود، در ظهر به کوتاهترین اندازهاش میرسد، و بعداز ظهر به تدریج بلندتر میگردد. هر گاه بعد از ظهر سایهٔ شاخص از روی کمان گذشت (یعنی سایهٔ شاخص هماندازهٔ پیش از ظهرش شد) آنجا را به عنوان نقطهٔ دوم علامتگذاری میکنیم. مانند روش پیشین، این نقطه سمت شرق و نقطهٔ پیشین سمت غرب را نشان میدهد.
در واقع هر دو نقطه سایهٔ همفاصله از شاخص، امتداد شرق-غرب را مشخص میکنند.
با اینکه روش پیشین نسبتاً دقیق است، این روش دقیقتر است؛ البته وقت بیشتری برای آن لازم است.
برای کشیدن کمان مثلاً طنابی(مانند بند کفش، نخ دندان) را انتخاب کنید. یک طرف طناب را به شاخص ببندید، و طرف دیگرش را به یک جسم تیز؛ به شکلی که وقتی طناب را میکشید دقیقاً به محل علامتگذاری شده برسد. نیمدایرهای روی زمین با جسم تیز رسم کنید.
وقتی سایهٔ شاخص به حداقل اندازهٔ خود میرسد(در ظهر شرعی)، این سایه سمت جنوب را نشان میدهد (بالای ۲۳٫۵ درجه).
جهتیابی با ساعت عقربهدار
ساعت مچی معمولی (آنالوگ، عقربهای) را به حالت افقی طوری در کف دست نگه میداریم که عقربهٔ ساعتشمار به سمت خورشید اشاره کند. در این حالت، نیمسازِ زاویهای که عقربهٔ ساعتشمار با عدد ۱۲ ساعت میسازد (زاویهٔ کوچکتر، نه بزرگتر)، جهت جنوب را نشان میدهد. یعنی مثلاً اگر چوبکبریتی را [به طور افقی] در نیمهٔ راه میان عقربهٔ ساعتشمار و عدد ۱۲ ساعت قرار دهید، به طور شمالی-جنوبی قرار گرفتهاست.
نکات
این که گفته شد عقربهٔ کوچک ساعت به سمت خورشید اشاره کند، یعنی اینکه اگر شاخصی [مثلاً چوبکبریت] ای که در مرکز ساعت قرار دهیم، سایهاش موازی با عقربهٔ ساعتشمار و در جهت مقابل آن باشد. یا اینکه سایهٔ عقربهٔ ساعتشمار درست در زیر خود عقربه قرار گیرد. یا مثلاً اگر چوبی ده-پانزده سانتیمتری را در زمین بهطور عمودی قرار دهیم، ساعت روی زمین به شکلی قرار گرفته باشد که عقربهٔ ساعتشمارش موازی با سایهٔ چوب باشد.
دلیل اینکه زاویه بین عقربهٔ ساعتشمار و ۱۲ را نصف میکنیم این است که: وقتی خوشید یک بار دور زمین میچرخد، ساعت ما دو دور میچرخد(دو تا ۱۲ ساعت). یعنی گرچه روز ۲۴ ساعت است (و یک دور کامل را در ۲۴ ساعت طی میکند)، ساعتهای ما یک دور کامل را در ۱۲ ساعت طی مینماید. اگر ساعت ۲۴ ساعتهای میداشتید، که دور آن به ۲۴ قسمت مساوی تقسیم شده بود، هر گاه عقربهٔ ساعتشمار را رو به خورشید میگرفتید عدد ۱۲ ساعت همیشه جهت جنوب را نشان میداد.
این روش وقتی سمت صحیح را نشان میدهد، که ساعت مورد نظر درست تنظیم شده باشد. یعنی اگر در بهار و تابستان ساعتها را نسبت به ساعت استاندارد یکساعت جلو میبرند، ما باید آن را تصحیح کنیم(ابتدا ساعتمان را یک ساعت عقب ببریم سپس روش را اِعمال کنیم؛ یا نیمساز عقربهٔ ساعتشمار را [به جای ۱۲] با ۱ حساب کنید). همچنین در همهٔ سطح یک کشور معمولاً ساعت یکسانی وجود دارد، که مثلاً در ایران حدود یک ساعت متغیر است (ایران تقریباً بین دو نصفالنهار قرار دارد؛ لذا ظهر شرعی در شرق و غرب ایران حدوداً یک ساعت فاصله دارد.) ساعت صحیح هر مکان همان ساعتی است که هنگام ظهر شرعی در آن در طول سال، اطراف ساعت ۱۲ ظهر است. در واقع برای تعیین دقیق جهتهای جغرافیایی ساعت باید طوری تنظیم باشد که هنگام ظهر شرعی ساعت ۱۲ را نشان دهد.
روش ساعت مچی تا ۲۴ درجه امکان خطا دارد. برای دقت بیشتر باید از آن در عرض جغرافیایی بین ۴۰ و ۶۰ درجه [شمالی یا جنوبی] استفاده شود؛ هر چند در عرض جغرافیایی ۲۳٫۵ تا ۶۶٫۵ درجه [شمالی یا جنوبی] نتیجهاش قابل قبول است.(البته در نیمکردهٔ جنوبی جهت شمال و جنوب برعکس است.) در واقع هر چه به استوا نزدیکتر شویم، از دقت این روش کاسته میشود. ضمناً هر چه زمان به کار بردن این روش به ظهر شرعی نزدیکتر باشد، نتیجهٔ آن دقیقتر خواهد بود.
اگر مطمئن نیستید کدام طرف شمال است و کدام طرف جنوب، به یاد بیاورید که خورشید از شرق بر میخیزد، در غرب مینشیند، و در ظهر سمت جنوب است.
توجه کنید که اگر این روش را در هنگام ظهر شرعی (یعنی ساعت ۱۲) اجرا کنیم، جهت عقربه ساعتشمار خود به سوی جنوب است. یعنی مانند همان روش «جهتیابی با سمت خورشید»، که گفتیم خورشید در ظهر شرعی به سمت جنوب است.
اگر از ساعت دیجیتال استفاده میکنید، میتوانید ساعت عقربهداری را روی یک کاغذ یا روی زمین بکشید (دور دایرهای از ۱ تا ۱۲ بنویسید، و عقربهٔ ساعتشمار را هم بکشید)، و سپس از روش بالا استفاده کنید.
حتی وقتی هوا آفتابی نیست و خورشید به راحتی دیده نمیشود هم گاه سایهٔ خوشید را میتوان دید. اگر یک چوبکبریت را عمود نگه دارید، سایهٔ آن برعکس جهت خورشید میافتد.
روشهای جهتیابی در شب
جهتیابی با ستارهٔ قطبی
از آنجا که ستارهها به محور ستاره قطبی در آسمان میچرخند، در نیمکرهٔ شمالی زمین ستارهٔ قطبی با تقریب بسیار خوبی (حدود ۰٫۷ درجه خطا) جهت شمال جغرافیایی (و نه شمال مغناطیسی) را نشان میدهد؛ یعنی اگر رو به آن بایستیم، رو به شمال خواهیم بود.
برای یافتن ستارهٔ قطبی روشهای مختلفی وجود دارد:
به وسیلهٔ مجموعه ستارگان «دبّ اکبر»: صورت فلکی دبّ اکبر شامل هفت ستارهاست که به شکل ملاقه قرار گرفتهاند: چهار ستاره آن تشکیل یک ذوزنقه را میدهند، و سه ستارهٔ دیگر مانند یک دنباله در ادامه ذوزنقه قرار گرفتهاند. هر گاه دو ستارهای که لبهٔ بیرونی ملاقه را تشکیل میدهند (دو ستارهٔ قاعده کوچک ذوزنقه؛ لبهٔ پیالهٔ ملاقه؛ محلی که آب از آنجا میریزد) را [با خطی فرضی] به هم وصل کنیم، و پنج برابر فاصله میان دو ستاره، به سمت جلو ادامه دهیم، به ستاره قطبی میرسیم.
به وسیلهٔ مجموعه ستارههای «ذاتالکرسی»: صورت فلکی ذاتالکرسی شامل پنج ستارهاست که به شکل W یا M قرار گرفتهاند. هرگاه (مطابق شکل) ستارهٔ وسط W (رأس زاویهٔ وسطی) را حدود پنج برابرِِ «فاصلهٔ آن نسبت به ستارههای اطراف» به سوی جلو ادامه دهیم، به ستارهٔ قطبی میرسیم.
نکات
صورتهای فلکی ذاتالکرسی و دبّ اکبر نسبت به ستارهٔ قطبی تقریباً روبهروی یکدیگر، و دور ستاره قطبی خلاف جهت عقربههای ساعت میچرخند. اگر یکی از آنها پشت کوه پنهان بود، با دیگری میتوان ستارهٔ قطبی را یافت. فاصلهٔ هر کدام از این دو صورت فلکی تا ستارهٔ قطبی تقریباً برابر است.
اگر برای یافتن ستارهها در آسمان از نقشه ستارهیاب (افلاکنما) استفاده میکنید، بهخاطر داشته باشید که ستارهیابها موقعیت ستارهها را در زمان، تاریخ و موقعیت جغرافیایی (طول و عرض جغرافیایی) خاصی نشان میدهند.
هر چه از استوا به سوی قطب شمال برویم، ستارهٔ قطبی در آسمان بالاتر (در ارتفاع بیشتر) دیده میشود. یعنی ستارهٔ قطبی در استوا (عرض جغرافیایی صفر درجه) تقریباً در افق دیده میشود، و در قطب شمال(عرض جغرافیایی ۹۰ درجه) تقریباً بالای سر (سرسو، سمتالرّأس، رأسالقدم) دیده میشود. بالاتر از عرض جغرافیایی ۷۰ درجه شمالی عملاً نمیتوان با ستارهٔ قطبی شمال را پیدا کرد.
جهتیابی با هلال ماه
اگر به دلیل وجود ابر یا درختان نمیتوانید ستارهها را ببینید، میتوانید از ماه برای جهتیابی استفاده کنید.
ماه به شکل هلال باریکی تولد مییابد، و در نیمههای ماه قمری به قرص کامل تبدیل میشود، و سپس در جهت مقابل هلالی میشود. در نیمهٔ اول ماههای قمری قسمت خارجی ماه (تحدب و کوژی ماه، برآمدگی و برجستگی ماه) مانند پیکانی جهت غرب را نشان میدهد. در نیمهٔ دوم ماههای قمری، تحدب ماه به سمت مشرق است.
اگر خطی از بالای هلال به پایین آن وصل کنیم و ادامه دهیم، در نیمهٔ اول ماه قمری شکل p و در نیمهٔ دوم شکل q خواهد داشت.
کره ماه در نیمهٔ اول ماههای قمری پیش از غروب آفتاب طلوع میکند، و در نیمهٔ دوم پس از غروب، تا پایان ماه که پس از نیمهشب طلوع مینماید.
پیدا کردن جنوب توسط ماه: اگر خطی فرضی میان دو نوک تیز هلال ماه رسم کرده و آن را تا زمین ادامه دهید، تقاطع امتداد این خط با افق، نقطه جنوب را [در نیمکرهٔ شمالی زمین] نشان میدهد.
این روش جهتیابی چندان دقیق نیست، ولی حداقل راهنمایی تقریبی را فراهم میسازد. در زمان قرص کامل نمیتوان از این روش استفاده کرد. وقتی ماه به صورت قرص کامل است، میتوان به کمک حرکت ظاهری ماه (که از مشرق به طرف مغرب است) جهتیابی کرد.
روشهای دیگر جهتیابی در شب
حرکت ظاهری ماه در آسمان از شرق به غرب است.
خوشه پروین: دستهای (حدود ده تا پانزده) ستاره، به شکل خوشه انگور، در یک جا مجتمع هستند که به آن مجموعه خوشه پروین میگویند. این ستارگان مانند خورشید از شرق به طرف غرب در حرکتند، ولی در همه حال دُمِ آنها به طرف مشرق است.
ستارگان بادبادکی: حدود هفت -هشت ستاره در آسمان وجود دارد که به شکل بادبادک یا علامت سوال میباشند. این ستارگان نیز از شرق به غرب حرکت میکنند، و در همه حال دنباله بادبادکی آنها بهطرف جنوب است.
کهکشان راه شیری تودهٔ عظیمی از انبوه ستارگان است که تقریباً از شمال شرقی به جنوب غربی امتداد یافتهاست. در شمال شرقی این راه باریک است، و هر چه به سمت جنوب غربی میرود، پهنتر میشود. هر چه به آخر شب نزدیکتر میشویم، قسمت پهن راه شیری به طرف مغرب منحرف میشود.
روشهای جهتیابی، قابل استفاده در روز و شب
جهتیابی با قبله
اگر جهت قبله و میزان انحراف آن از جنوب (یا دیگر جهتهای اصلی) را بدانیم، میتوانیم شمال را تشخیص دهیم. مثلاً اگر در تهران ۳۷ درجه از جنوب سمت به غرب متمایل شویم (یعنی حدوداً جنوب غربی)، به طرف قبله ایستادهایم. پس هرگاه در تهران جهت قبله را بدانیم، اگر ۳۷ درجه از سمت قبله در جهت عکس عقربههای ساعت بچرخیم، به طرف جنوب ایستادهایم، و اگر ۱۴۳ درجه (۳۷-۱۸۰) در جهت عقربههای ساعت بچرخیم، به طرف شمال ایستادهایم.
قبله را از راههای مختلفی میتوان یافت:
قبلهنما: دقیقترین روش تعیین قبله، بهوسیلهٔ قبلهنماست، که آن هم با یک قطبنما انجام میگیرد؛ و اگر ما قطبنما داشته باشیم، با آن قطب را مشخص میکنیم!
محراب مسجد: محراب مساجد به طرف قبلهاست. در نمازخانهها هم معمولاً جهت قبله مشخص شدهاست.
قبرستان: مرده را در قبر روی دست راست، به سمت قبله میخوابانند. پس اگر شما طوری ایستاده باشید که نوشتههای سنگ قبر را به درستی میخوانید، سمت چپتان قبلهاست.
دستشویی: از آنجا که قضای حاجت رو به قبله نباید باشد، معمولاً توالتها را عمود بر قبله میسازند.
جهتیابی با قطبنمای دستساز
اگر قطبنمایی به همراه نداشتید، ولی اتفاقاً یک سوزن یا میخ کوچک در جیبتان یافتید، این روش کمککار شما در ساخت یک قطبنما خواهد بود. البته احتمال استفاده از آن در شرایط واقعی کم است، ولی انجام آن کاری سرگرمکنندهاست.
با مالش دادن یک سوزن فقط در یک جهت به آهنربا -یا حتی احتمالاً چاقوی خودتان-، یا مالیدن آن فقط در یک جهت به پارچهٔ ابریشمی یا پنبهای، سوزنْ مغناطیسی یا قطبی میشود؛ مانند سوزن قطبنما. (مثلاً با ۳۰ بار مالش دادن سوزن به آهنربا از طرف خودتان به سمت بیرون، سوزن به اندازهٔ کافی خاصیت آهنربایی پیدا میکند. همچنین مالش سر سوزن از پایین به بالا بر پارچهٔ ابریشمی باعث میشود که سر سوزن نقطه شمال را نشان دهد). حتی میتوانید آنرا در یک جهت میان موهای سر خود بکشید. توجه کنید که همیشه فقط در یک جهت مالش دهید.
حال اگر آنرا روی یک چوبپنبه یا پوشال کوچک قرار دهید(سوزن را به چوبپنبه چسب بزنید، یا درون آن فرو کنید؛ یا در دو طرف سوزن چوبپنبههایی کوچک فرو کنید)، و روی آب (آب راکد یا ظرفی پر از آب) شناور نمایید، مانند یک قطبنما عمل میکند، و سر سوزن رو به شمال میچرخد. برای اینکه سمت شمال و جنوب سوزن را اشتباه نکنید، این نکته را در نظر بگیرید که -در نیمکرهٔ شمالی زمین- آن سمت قطبنما که تقریباً رو به خورشید و ماه است، سمت جنوب است، زیرا آنها در قسمت جنوبی آسمان قرار دارند. همچنین میتوانید سوزن را با یک آهنربا امتحان کنید، و سپس سمت شمال را با علامتی روی آن مشخص نمایید.
روش دیگر ساخت آهنربا این است که یک میله یا سوزن آهنی یا فولادی را در جهت میدان مغناطیسی زمین تراز کنیم، و سپس آنرا حرارت داده یا بر آن ضربه وارد کنیم. حال اگر این آهنربا را روی سطحی با اصطکاک کم قرار دهیم (روی یک تکه چوب کوچک در آب شناور سازید، یا مثلاً سوزن را با یک ریسمان غیرفلزی آویزان(معلق) نمایید) قطبنمای ما کار میکند؛ یعنی میله آنقدر میچرخد تا در راستای میدان مغناطیسی زمین (شمالی-جنوبی) قرار گیرد.
مغناطیسی کردن سوزن با باتری: اگر سیمی را دور سوزن بپیچانید و برای چند دقیقه سر سیم را به ته باتری وصل کنید، سوزن مغناطیسی میشود.
به دلیل کشش سطحی آب، میتوان سوزن را به تنهایی روی سطح آن شناور کرد. مثلاً میتوان سوزن را روی کاغذی گذاشت، و کاغذ را روی آب گذاشت. اگر کاغذ روی آب بماند که بهتر، و اگر کاغذ در آب فرو برود احتمالاً سوزن روی آب باقی میماند. اگر سوزن را با گریس یا روغنی غیرقابلحل در آب چرب کنید (مثلاً با مالش سوزن به موهای خود سوزن را چرب نمایید)، کار آسانتر خواهد شد. چرب بودن سوزن سبب میشود که سوزن روی سطح آب شناور بماند.