








سونوگرافی فراصوتی
سونوگرافی فراصوتی
سونوگرافی فراصوتی یکی از روشهای تشخیص بیماری در پزشکی است. به این روش اکوگرافی، پژواکنگاری و صوتنگاری نیز گفته میشود. این روش بر مبنای امواج فراصوت و برای بررسی بافتهای زیرجلدی مانند عضلات، مفاصل، تاندونها و اندامهای داخلی بدن و ضایعات آنها پی ریزی شدهاست. سونوگرافی در حاملگی نیز کاربردهای وسیعی دارد. همچنین امروزه سونوگرافی کاربردهای درمانی نیز دارد.

ریشه لغوی
کلمه سونوگرافی از لفظ لاتین sono به معنی صوت و نیز graphic به معنی شکل و ترسیم گرفته شده و ultrasound از ultra به معنی ماورا و نیز sound به معنی صوت یا صدا گرفته شدهاست.
تاریخچه
در سال ۱۸۷۶ میلادی، فرانسیس گالتون برای اولین بار پی به وجود امواج فراصوت برد. در زمان جنگ جهانی اول کشور انگلستان برای کمک به جلوگیری از غرق شدن کشتیهایش توسط زیردریاییهای کشور آلمان در اقیانوس آتلانتیک شمالی دستگاه کشف کننده زیردریاییها به کمک امواج صوتی به نام صوتیاب (Sonar) ابداع کرد. این دستگاه امواج فراصوت تولید میکرد که در پیدا کردن مسیر کشتیها استفاده میشد. این تکنیک در زمان جنگ جهانی دوم تکمیل گردید و بعدها بطور گستردهای در صنعت این کشور برای آشکار سازی شکافها در فلزات و سایر موارد مورد استفاده قرار میگرفت. از کاربرد بخصوصی که انعکاس صوت در جنگ و صنعت داشت صوتیاب به علم پزشکی وارد شد و تبدیل به یک وسیله تشخیصی بزرگ در علم پزشکی گردید.
سیر تحولی در رشد
نخستین دستگاه تولید کننده امواج فراصوت در پزشکی، در سال ۱۹۳۷ میلادی توسط دوسیک اختراع شد و روی مغز انسان آزمایش شد. اگر چه فراصوت در ابتدا فقط برای مشخص کردن خط وسط مغز بود، اکنون بصورت یک روش تشخیصی و درمانی مهم درآمده و پیشرفت روز به روز انواع نسلهای دستگاههای تولید فراصوت، تحولات عظیمی در تشخیص و درمان در علم پزشکی بوجود آوردهاست. اگرچه بر اساس آماری که در سال ۲۰۰۰ گرفته شده اولتراسوند بعلت هزینه پایینتر، ایمنی بیشتر، حمل و نقل آسان وامکان ارائه تصاویر زنده بیشترین کاربرد را در مقایسه با سایر روشهای تصویربرداری دارد ولی بر اساس آمار به ترتیب سی. تی. اسکن (CT) و ام. آر. آی (MRI) و پس از آن تصویربرداری هستهای بهویژه مقطعنگاری پوزیترون (PET) بیشترین کاربرد را دارند چراکه سامانه فراصوتی دارای محدودیتهایی نیز هست از جمله:
امواج فراصوت قابلیت عبور از استخوان را ندارند. همچنین از گاز و هوا نیز نمیتوانند عبور کنند و بازتاب پیدا میکنند. بنابراین روش ایدهآلی برای تصویربرداری از سینه، روده و معده نمیباشند. گازهای رودهای جلوی تصویربرداری از ساختمانهای داخلیتر مثل پانکراس و آئورت را میگیرند. دیگراینکه امواج در بافتها افت کرده و بهعنوان مثال، این مساله تصویر برداری از قلب افراد چاق را با مشکل مواجه میکند.
تعریف امواج فراصوت
امواج فراصوت به شکلی از انرژی از امواج مکانیکی گفته میشود که فرکانس آنها بالاتر از حد شنوایی انسان باشد. گوش انسان قادر است امواج بین ۲۰ هرتز تا ۲۰۰۰۰ هرتز را بشنود. هر موج (شنوایی یا فراصوت) یک آشفتگی مکانیکی در یک محیط گاز، مایع و یا جامد است که به بیرون از چشمه صوتی و با سرعتی یکنواخت و معین حرکت میکند. در حرکت یا گسیل موج مکانیکی، ماده منتقل نمیشود. اگر ارتعاش ذرات در جهت عمود بر انتشار صوت باشد، موج عرضی است که بیشتر در جامدات رخ میدهد و در صورتی که ارتعاش در راستای انتشار امواج باشد، موج طولی است. انتشار در بافتهای بدن به صورت امواج طولی است. از این رو در پزشکی با اینگونه امواج (بالای ۲۰٬۰۰۰ hertz) سر و کار داریم. در کاربردهای تصویر برداری پزشکی، امواج فراصوت در رنج فرکانسی ۲ تا ۲۰ مگاهرتز به کار گرفته میشوند. فرکانسهای بالاتر از این میزان کاربردهای تحقیقاتی و آزمایشگاهی دارند.
روشهای تولید امواج فراصوت
روش پیزوالکتریسیته تأثیر متقابل فشار مکانیکی و نیروی الکتریکی را در یک محیط اثر پیزو الکتریسیته میگویند. بطور مثال بلورهایی وجود دارند که در اثر فشار مکانیکی، نیروی الکتریکی تولید میکنند و برعکس ایجاد اختلاف پتانسیل در دو سوی همین بلور و در همین راستا باعث فشردگی و انبساط آنها میشود که ادامه دادن به این فشردگی و انبساط باعث نوسان و تولید امواج میشود. مواد (بلورهای) دارای این ویژگی را مواد پیزو الکتریک میگویند. اثر پیزو الکتریسیته فقط در بلورهایی که دارای تقارن مرکزی نیستند، وجود دارد. بلور کوارتز از این دسته مواد است و اولین مادهای بود که برای ایجاد امواج فراصوت از آن استفاده میشد که اکنون هم استفاده میشود.
اگر چه مواد متبلور طبیعی که دارای خاصیت پیزو الکتریسیته باشند، فراوان هستند. ولی در کاربرد امواج فراصوت در پزشکی از کریستالهایی استفاده میشود که سرامیکی بوده و بطور مصنوعی تهیه میشوند. از نمونه این نوع کریستالها، مخلوطی از زیرکونیت و تیتانیت سرب (Lead zirconat & Lead titanat) است که به شدت دارای خاصیت پیزوالکتریسیته هستند. به این مواد که واسطهای برای تبدیل انرژی الکتریکی به انرژی مکانیکی و بالعکس هستند، مبدل یا ترانسدیوسر (transuscer) میگویند. یک ترانسدیوسر فراصوتی بکار میرود که علامت الکتریکی را به انرژی فراصوت تبدیل کند که به داخل بافت بدن نفوذ و انرژی فراصوت انعکاس یافته را به علامت الکتریکی تبدیل کند.
روش مگنتو استریکسیون
این خاصیت در مواد فرومغناطیس (مواد دارای دو قطبیهای مغناطیسی کوچک بطور خود به خود با دو قطبیهای مجاور خود همخط شوند) تحت تأثیر میدان مغناطیسی بوجود میآید. مواد مزبور در این میدانها تغییر طول میدهند و بسته به فرکانس (شمارش زنشهای کامل موج در یک ثانیه) جریان متناوب به نوسان در میآیند و میتوانند امواج فراصوت تولید کنند. این مواد در پزشکی کاربرد ندارند و شدت امواج تولید شده به این روش کم است و بیشتر کاربرد آزمایشگاهی دارد.
عملکرد دستگاههای تصویربرداری و تشخیص با امواج فراصوت
در سیستمهای فراصوت، پالسهای مکانیکی با فرکانسی در محدودهٔ فراصوت، توسط پراب مخصوص منتشر میگردد. این پرابها دارای آرایهای از فرستندههای فرا صوت میباشد. بخشی از امواج منتشر شده در محیط (در اینجا بافتهای زیستی)، با برخورد به مرزهای دو بافت با چگالی متفاوت، دچار بازتابش (اکو) میگردند. میزان این بازتابش وابسته به امپدانس انتشار امواج فراصوت در دو محیط میباشد. اساس سیستمهای تصویربرداری آلتراسوند، تشخیص تاخیرهای سیگنالهای دریافتی و پالسهای ارسال شده میباشد.
در کاربردهای پزشکی، امواج فراصوت با فرکانسهایی در رنج ۱ مگاهرتز الی ۱۸ مگاهرتز، به کار گرفته میشود. فرکانسهای بالا نیاز به فرستندههایی با ابعاد کوچکتر داشته و با توجه به کوتاه تر شدن طول موج، امکان دستیابی به رزولوشن بالاتر را فراهم میآورد، اما با این وجود، میزان تضعیف سیگنال در محیط انتشار، با افزایش فرکانس، افزایش مییابد. به همین دلیل رنج فرکانس معمول ۳ الی ۵ مگاهرتز میباشد.
برای تشخیص سرعت سیالات، مانند سرعت جریان خون، میتوان از اثر داپلی نیز بهره برد. با توجه به اثر دوپلر حرکت سیال موجب ایجاد شیفت فرکانسی در امواج بازتابیده شده میشود. میزان این شیفت فرکانس وابسته به اندازه و جهت سرعت میباشد.
با افزایش فرکانس، الگوی تابش فرستنده به حالت ایزوتروپیک نزدیک میگردد. برای متمرکز نمودن پالسهای ارسالی در یک راستا و حتی یک نقطه خاص میبایست از پرابهای آرایه فازی، استفاده نمود. این پرابها شامل چندین فرستنده/گیرنده پیزوالکتریک بر روی خود میباشند که میتوان به صورت یک ردیف (یک بعدی) و یا چندین ردیف (دو بعدی) کنار هم چیده شده باشند. در حالت پسیو، میتوان چیدمان این المانها را به نحوی طراحی نمود که لوب اصلی الگوی تابش آنتن در یک راستای خاص متمرکز گردد.
در حالت اکتیو فاز، با ایجاد تاخیرهای کنترل شده، در پالسهای ارسالی توسط هر المنت، میتوان جهت لوب اصلی را نیز بدون تغییر موقعیت مکانیکی فرستنده، تغییر داد. در فرستندههای آرایه فازی دو بعدی اکتیو، امکان فوکوس کردن در یک نقطه خاص نیز فراهم میآید. این خصوصیت امکان ایجاد تصاویر دو بعدی و سه بعدی را بدون تغییر دادن مکان پراب، فراهم میآورد.
کاربرد امواج فراصوت
۱. کاربرد تشخیصی (سونوگرافی)
2. بیماریهای زنان و زایمان (Gynecology) مانند بررسی قلب جنین، اندازهگیری قطر سر (سن جنین)، بررسی جایگاه اتصال جفت و محل ناف، تومورهای پستان. 3. بیماریهای مغز و اعصاب(Neurology) مانند بررسی تومور مغزی، خونریزی مغزی به صورت اکوگرام مغزی یا اکوانسفالوگرافی.
4. بیماریهای چشم (ophthalmology) مانند تشخیص اجسام خارجی در درون چشم، تومور عصبی، خونریزی شبکیه، اندازهگیری قطر چشم، فاصله عدسی از شبکیه.
5. بیماریهای کبدی (Hepatic) مانند بررسی کیست و آبسه کبدی.
6. بیماریهای قلبی (cardiology) مانند بررسی اکوکاردیوگرافی.
۷. دندانپزشکی مانند اندازهگیری ضخامت بافت نرم در حفرههای دهانی. و نیز کاربردهای درمانی آن مانند جرم گیری لثه
۸. این امواج به علت اینکه مانند تشعشعات یونیزان عمل نمیکنند. بنابراین برای زنان و کودکان بیخطر هستند. ۹. همچنین برای تصویربرداری از سینه هااستفاده میشود. ۱۰. رزولوشن بالایی از این روش، برای تصویربرداری از بافتهای سطحی و سلولهای نزدیک سطح پوست استفاده میشود. کاربرد درمانی (سونوتراپی): ۱. در فیزیوتراپی جهت کاهش درد و التهاب و همچنین انعطافپذیری بافتها از اولترا سوند استفاده میگردد.
۲. کاربرد گرمایی 11. تزریق بدون جراحت با جذب امواج فراصوت بهوسیله بدن بخشی از انرژی آن به گرما تبدیل میشود. گرمای موضعی حاصل از جذب امواج فراصوت بهبودی را تسریع میکند. قابلیت کشسانی کلاژن (پروتئینی ارتجاعی) را افزایش میدهد. کشش در جوشگاههای زخم (scars) افزایش میدهد و باعث بهبود آنها میشود. اگر اسکار به بافتهای زیرین خود چسبیده باشد، باعث آزاد شدن آنها میشود. گرمای حاصل از امواج فراصوت با گرمای حاصل از گرمایش متفاوت است.
میکروماساژ مکانیکی
به هنگام فشردگی و انبساط محیط، امواج طولی فراصوتی روی بافت اثر میگذارند و باعث جابجایی آب میان بافتی و در نتیجه باعث کاهش ورم (تجمع آب میان بافتی در اثر ضربه به یک محل) میشوند.
درمان آسیب تازه و ورم:آسیب تازه معمولاً با ورم همراه است. فراصوت در بسیاری از موارد برای از بین بردن مواد دفعی در اثر ضربه و کاهش خطر چسبندگی بافتها بهم بکار میرود.
درمان ورم کهنه یا مزمن: فراصوت چسبندگیهایی که میان ساختمانهای مجاور ممکن است ایجاد شود را میشکند.
خطرات فراصوت
جستجو در ویکیانبار در ویکیانبار پروندههایی دربارهٔ سونوگرافی فراصوتی موجود است.
سوختگی
اگر امواج پیوسته و در یک مکان بدون چرخش بکار روند، در بافت باعث سوختگی میشود و باید امواج حرکت داده شوند.
پارگی کروموزومی
استفاده دراز مدت از امواج اولتراسوند با شدت خیلی بالا پارگی در رشته دی ان ای (DNA) را نشان میدهد.
ایجاد حفره
یکی از عوامل کاهش انرژی امواج اولتراسوند هنگام گذشتن از بافتهای بدن ایجاد حفره یا کاویتاسیون است. همه محلولها شامل مقدار قابل ملاحظهای حبابهای گاز غیر قابل دیدن هستند و دامنه بزرگ نوسانهای امواج اولتراسوند در داخل محلولها میتواند بر روی بافتها تغییرات بیولوژیکی ایجاد کند (پارگی در دیواره یاختهها و از هم گسستن مولکولهای بزرگ).
عایق صوتی
هر وسیلهای برای کاهش فشار صوتی با توجه به صدای منبع و گیرنده را عایق صوتی (به انگلیسی: Soundproofing) میگویند.
چندین روش اساسی برای کاهش صدا وجود دارد: افزایش فاصله بین منبع و گیرنده، با استفاده از موانع سر و صدا برای منعکس یا جذب انرژی از امواج صوتی است، با استفاده از سازههای میرایی مانند تیغههای صوتی، و یا با استفاده از عایقهای صوتی.
فواید استفاده از عایق صوتی
بهبود صدا در یک اتاق (اتاق بدون پژواک)
کاهش نشت صدا به / از اتاق مجاور و یا خارج از منزل
آکوستیک آرام بخش
کاهش سر و صدا
کنترل سر و صدا
محدود کردن سر و صدای ناخواسته
عایق صوتی میتواند از امواج صوتی ناخواسته غیر مستقیم مانند سرکوب بازتاب که باعث پژواک جلوگیری کند عایق صوتی میتواند انتقال امواج ناخواسته صدای مستقیم از منبع به شنونده غیر ارادی از طریق کاهش استفاده از فاصله و دخالت اشیاء در مسیر صدا مسیر سازد
روشهای ساده عایقکاری صوتی
1. بستن منافذ ورود و خروج هوا. هر منفذی که هوا بتواند از آن عبور کند،صدا را هم می تواندانتقال دهد. کلیه منافذ موجود در سقفها و دیوارهانظیر اطراف جعبه تقسیم های برق، کانالها و داکتها ،سیم ها و هرجایی راکه شیئی از داخل دیوار یا سقف عبور می کند با بتونه یا فوم پلی اورتان درزگیری نمایید.
2. جلوگیری از ایجاد "کانالهای عبور صدا " در دیوارها. هنگام ساخت بناهای جدید ، کلیدهای برق و دریچه های هوا را در داخل دیوارمشترک دو فضا ، پشت به پشت هم قرار ندهید.
3. اجتناب از استفاده از مصالح سخت. زیرا اینگونه مصالح ,صوت را به آسانی ازیک مکان به مکان دیگر انتقال می دهند.
4. استفاده از یک لایه انعطاف پذیرنظیر فوم منبسط شونده ، جهت جدا نمودن لوله ها از غلافها یا سوراخهایی که از آن عبور می کنند.
5. استفاده از عایق صوتی در دیوارهای ساختمانهای جدید جهت جلوگیری ازانتقال صدا بین اتاقهای مجاور. به منظور جلوگیری از انتقال صدای نامطلوب جریان سریع آب به هنگام تخلیه فلاش تانک توالت، لوله های پلاستیکی تخلیه آب را عایق بندی کنید.
6. استفاده از وسایل خانگی آرامتر، حتی اگر گرانتر از موارد مشابه پرصداتر باشند.
7. جدا نمودن تجهیزات صدادار از محلهای استراحت. استفاده از اطاقهای مجزای مجهز به عایق های صوتی می تواند ایده خوبی درطراحی منزل باشد. بکارگیری درهای مجهز به عایق بین کلیه فضاها ، به مقدار قابل ملاحظه ای از انتقال صدا در خانه جلوگیری می کند.
8. استفاده از مصالح جاذب صدا در کفها، دیوارها و سقفها. عایقهای صوتی به مانند موکت می توانند از عبور صدا جلوگیری نمایند. حتی الامکان ازبکارگیری کفپوشهای سخت، مانند سرامیک، بتن و چوب خودداری نمایید.
صوتشناسی
صوتشناسی یا آکوستیک یکی از شاخههای علم فیزیک است و موضوع آن بررسی موج های مکانیکی در گازها ، مایع ها و جامدها ،از جمله نوسان ها ، صدا ، فراصوت و فروصوت است.کاربردهای آکوستیک در بسیاری از جنبه های زندگی امروز دیده می شوند و ساده ترین نمونه آن صنایع صوتی و نیز کنترل نویز (مکانیکی)است.
واژه ی آکوستیک برگرفته از ریشه ی یونانی ακουστικός ، به معنای "برای و از شنوایی" و نیز از ἀκουστός به معنای قابل شنیدن است.
تاریخچه
از نظر اهمیتی که آکوستیک یا علم صدا دارا میباشد میتوان انتظار داشت که این موضوع در تاریخ علوم فیزیک جزو مطالب اساسی به شمار رفته باشد، در صورتی که چنین چیزی نیست، زیرا در قبال تاریخ سایر علوم، تاریخ آکوستیک قسمت از قلم افتاده و مهجوری بیش نیست. یکی از دلایل این مهجوریت تاریخی این است که نظریه اساسی اصلی راجع به انتشار و اخذ صوت از زمانهای بسیار قدیم در تحولات فکر بشری پیدا شده و اسلوب این فکر همان است که امروزه مورد قبول ماست.
تولید صوت
وقتی که به یک جسم جامد ضربه وارد میسازیم، تولید صدا میکند. تحت بعضی از شرایط صدای حاصل، بگوش انسان خوش آیند و مطبوع است و این در واقع اساس پیدایش علم موسیقی است که سالیان دراز قبل از تاریخ ضبط صوت، موجود بوده است، اما موسیقی، قرنها قبل از نظر علمی مورد تحقیق قرار گیرد، جزو صنایع ظریفه محسوب میگردید. این مطلب مورد قبول عموم است که اولین فیلسوف یونانی که مبنای موسیقی را برسی نموده است. فیثاغورث میباشد که ۶ قرن قبل از میلاد زندگی میکرده است.
سونوگرافی فراصوتی یکی از روشهای تشخیص بیماری در پزشکی است. به این روش اکوگرافی، پژواکنگاری و صوتنگاری نیز گفته میشود. این روش بر مبنای امواج فراصوت و برای بررسی بافتهای زیرجلدی مانند عضلات، مفاصل، تاندونها و اندامهای داخلی بدن و ضایعات آنها پی ریزی شدهاست. سونوگرافی در حاملگی نیز کاربردهای وسیعی دارد. همچنین امروزه سونوگرافی کاربردهای درمانی نیز دارد.
ریشه لغوی
کلمه سونوگرافی از لفظ لاتین sono به معنی صوت و نیز graphic به معنی شکل و ترسیم گرفته شده و ultrasound از ultra به معنی ماورا و نیز sound به معنی صوت یا صدا گرفته شدهاست.
تاریخچه
در سال ۱۸۷۶ میلادی، فرانسیس گالتون برای اولین بار پی به وجود امواج فراصوت برد. در زمان جنگ جهانی اول کشور انگلستان برای کمک به جلوگیری از غرق شدن کشتیهایش توسط زیردریاییهای کشور آلمان در اقیانوس آتلانتیک شمالی دستگاه کشف کننده زیردریاییها به کمک امواج صوتی به نام صوتیاب (Sonar) ابداع کرد. این دستگاه امواج فراصوت تولید میکرد که در پیدا کردن مسیر کشتیها استفاده میشد. این تکنیک در زمان جنگ جهانی دوم تکمیل گردید و بعدها بطور گستردهای در صنعت این کشور برای آشکار سازی شکافها در فلزات و سایر موارد مورد استفاده قرار میگرفت. از کاربرد بخصوصی که انعکاس صوت در جنگ و صنعت داشت صوتیاب به علم پزشکی وارد شد و تبدیل به یک وسیله تشخیصی بزرگ در علم پزشکی گردید.
سیر تحولی در رشد
نخستین دستگاه تولید کننده امواج فراصوت در پزشکی، در سال ۱۹۳۷ میلادی توسط دوسیک اختراع شد و روی مغز انسان آزمایش شد. اگر چه فراصوت در ابتدا فقط برای مشخص کردن خط وسط مغز بود، اکنون بصورت یک روش تشخیصی و درمانی مهم درآمده و پیشرفت روز به روز انواع نسلهای دستگاههای تولید فراصوت، تحولات عظیمی در تشخیص و درمان در علم پزشکی بوجود آوردهاست. اگرچه بر اساس آماری که در سال ۲۰۰۰ گرفته شده اولتراسوند بعلت هزینه پایینتر، ایمنی بیشتر، حمل و نقل آسان وامکان ارائه تصاویر زنده بیشترین کاربرد را در مقایسه با سایر روشهای تصویربرداری دارد ولی بر اساس آمار به ترتیب سی. تی. اسکن (CT) و ام. آر. آی (MRI) و پس از آن تصویربرداری هستهای بهویژه مقطعنگاری پوزیترون (PET) بیشترین کاربرد را دارند چراکه سامانه فراصوتی دارای محدودیتهایی نیز هست از جمله:
امواج فراصوت قابلیت عبور از استخوان را ندارند. همچنین از گاز و هوا نیز نمیتوانند عبور کنند و بازتاب پیدا میکنند. بنابراین روش ایدهآلی برای تصویربرداری از سینه، روده و معده نمیباشند. گازهای رودهای جلوی تصویربرداری از ساختمانهای داخلیتر مثل پانکراس و آئورت را میگیرند. دیگراینکه امواج در بافتها افت کرده و بهعنوان مثال، این مساله تصویر برداری از قلب افراد چاق را با مشکل مواجه میکند.
تعریف امواج فراصوت
امواج فراصوت به شکلی از انرژی از امواج مکانیکی گفته میشود که فرکانس آنها بالاتر از حد شنوایی انسان باشد. گوش انسان قادر است امواج بین ۲۰ هرتز تا ۲۰۰۰۰ هرتز را بشنود. هر موج (شنوایی یا فراصوت) یک آشفتگی مکانیکی در یک محیط گاز، مایع و یا جامد است که به بیرون از چشمه صوتی و با سرعتی یکنواخت و معین حرکت میکند. در حرکت یا گسیل موج مکانیکی، ماده منتقل نمیشود. اگر ارتعاش ذرات در جهت عمود بر انتشار صوت باشد، موج عرضی است که بیشتر در جامدات رخ میدهد و در صورتی که ارتعاش در راستای انتشار امواج باشد، موج طولی است. انتشار در بافتهای بدن به صورت امواج طولی است. از این رو در پزشکی با اینگونه امواج (بالای ۲۰٬۰۰۰ hertz) سر و کار داریم. در کاربردهای تصویر برداری پزشکی، امواج فراصوت در رنج فرکانسی ۲ تا ۲۰ مگاهرتز به کار گرفته میشوند. فرکانسهای بالاتر از این میزان کاربردهای تحقیقاتی و آزمایشگاهی دارند.
روشهای تولید امواج فراصوت
روش پیزوالکتریسیته تأثیر متقابل فشار مکانیکی و نیروی الکتریکی را در یک محیط اثر پیزو الکتریسیته میگویند. بطور مثال بلورهایی وجود دارند که در اثر فشار مکانیکی، نیروی الکتریکی تولید میکنند و برعکس ایجاد اختلاف پتانسیل در دو سوی همین بلور و در همین راستا باعث فشردگی و انبساط آنها میشود که ادامه دادن به این فشردگی و انبساط باعث نوسان و تولید امواج میشود. مواد (بلورهای) دارای این ویژگی را مواد پیزو الکتریک میگویند. اثر پیزو الکتریسیته فقط در بلورهایی که دارای تقارن مرکزی نیستند، وجود دارد. بلور کوارتز از این دسته مواد است و اولین مادهای بود که برای ایجاد امواج فراصوت از آن استفاده میشد که اکنون هم استفاده میشود.
اگر چه مواد متبلور طبیعی که دارای خاصیت پیزو الکتریسیته باشند، فراوان هستند. ولی در کاربرد امواج فراصوت در پزشکی از کریستالهایی استفاده میشود که سرامیکی بوده و بطور مصنوعی تهیه میشوند. از نمونه این نوع کریستالها، مخلوطی از زیرکونیت و تیتانیت سرب (Lead zirconat & Lead titanat) است که به شدت دارای خاصیت پیزوالکتریسیته هستند. به این مواد که واسطهای برای تبدیل انرژی الکتریکی به انرژی مکانیکی و بالعکس هستند، مبدل یا ترانسدیوسر (transuscer) میگویند. یک ترانسدیوسر فراصوتی بکار میرود که علامت الکتریکی را به انرژی فراصوت تبدیل کند که به داخل بافت بدن نفوذ و انرژی فراصوت انعکاس یافته را به علامت الکتریکی تبدیل کند.
روش مگنتو استریکسیون
این خاصیت در مواد فرومغناطیس (مواد دارای دو قطبیهای مغناطیسی کوچک بطور خود به خود با دو قطبیهای مجاور خود همخط شوند) تحت تأثیر میدان مغناطیسی بوجود میآید. مواد مزبور در این میدانها تغییر طول میدهند و بسته به فرکانس (شمارش زنشهای کامل موج در یک ثانیه) جریان متناوب به نوسان در میآیند و میتوانند امواج فراصوت تولید کنند. این مواد در پزشکی کاربرد ندارند و شدت امواج تولید شده به این روش کم است و بیشتر کاربرد آزمایشگاهی دارد.
عملکرد دستگاههای تصویربرداری و تشخیص با امواج فراصوت
در سیستمهای فراصوت، پالسهای مکانیکی با فرکانسی در محدودهٔ فراصوت، توسط پراب مخصوص منتشر میگردد. این پرابها دارای آرایهای از فرستندههای فرا صوت میباشد. بخشی از امواج منتشر شده در محیط (در اینجا بافتهای زیستی)، با برخورد به مرزهای دو بافت با چگالی متفاوت، دچار بازتابش (اکو) میگردند. میزان این بازتابش وابسته به امپدانس انتشار امواج فراصوت در دو محیط میباشد. اساس سیستمهای تصویربرداری آلتراسوند، تشخیص تاخیرهای سیگنالهای دریافتی و پالسهای ارسال شده میباشد.
در کاربردهای پزشکی، امواج فراصوت با فرکانسهایی در رنج ۱ مگاهرتز الی ۱۸ مگاهرتز، به کار گرفته میشود. فرکانسهای بالا نیاز به فرستندههایی با ابعاد کوچکتر داشته و با توجه به کوتاه تر شدن طول موج، امکان دستیابی به رزولوشن بالاتر را فراهم میآورد، اما با این وجود، میزان تضعیف سیگنال در محیط انتشار، با افزایش فرکانس، افزایش مییابد. به همین دلیل رنج فرکانس معمول ۳ الی ۵ مگاهرتز میباشد.
برای تشخیص سرعت سیالات، مانند سرعت جریان خون، میتوان از اثر داپلی نیز بهره برد. با توجه به اثر دوپلر حرکت سیال موجب ایجاد شیفت فرکانسی در امواج بازتابیده شده میشود. میزان این شیفت فرکانس وابسته به اندازه و جهت سرعت میباشد.
با افزایش فرکانس، الگوی تابش فرستنده به حالت ایزوتروپیک نزدیک میگردد. برای متمرکز نمودن پالسهای ارسالی در یک راستا و حتی یک نقطه خاص میبایست از پرابهای آرایه فازی، استفاده نمود. این پرابها شامل چندین فرستنده/گیرنده پیزوالکتریک بر روی خود میباشند که میتوان به صورت یک ردیف (یک بعدی) و یا چندین ردیف (دو بعدی) کنار هم چیده شده باشند. در حالت پسیو، میتوان چیدمان این المانها را به نحوی طراحی نمود که لوب اصلی الگوی تابش آنتن در یک راستای خاص متمرکز گردد.
در حالت اکتیو فاز، با ایجاد تاخیرهای کنترل شده، در پالسهای ارسالی توسط هر المنت، میتوان جهت لوب اصلی را نیز بدون تغییر موقعیت مکانیکی فرستنده، تغییر داد. در فرستندههای آرایه فازی دو بعدی اکتیو، امکان فوکوس کردن در یک نقطه خاص نیز فراهم میآید. این خصوصیت امکان ایجاد تصاویر دو بعدی و سه بعدی را بدون تغییر دادن مکان پراب، فراهم میآورد.
کاربرد امواج فراصوت
۱. کاربرد تشخیصی (سونوگرافی)
2. بیماریهای زنان و زایمان (Gynecology) مانند بررسی قلب جنین، اندازهگیری قطر سر (سن جنین)، بررسی جایگاه اتصال جفت و محل ناف، تومورهای پستان. 3. بیماریهای مغز و اعصاب(Neurology) مانند بررسی تومور مغزی، خونریزی مغزی به صورت اکوگرام مغزی یا اکوانسفالوگرافی.
4. بیماریهای چشم (ophthalmology) مانند تشخیص اجسام خارجی در درون چشم، تومور عصبی، خونریزی شبکیه، اندازهگیری قطر چشم، فاصله عدسی از شبکیه.
5. بیماریهای کبدی (Hepatic) مانند بررسی کیست و آبسه کبدی.
6. بیماریهای قلبی (cardiology) مانند بررسی اکوکاردیوگرافی.
۷. دندانپزشکی مانند اندازهگیری ضخامت بافت نرم در حفرههای دهانی. و نیز کاربردهای درمانی آن مانند جرم گیری لثه
۸. این امواج به علت اینکه مانند تشعشعات یونیزان عمل نمیکنند. بنابراین برای زنان و کودکان بیخطر هستند. ۹. همچنین برای تصویربرداری از سینه هااستفاده میشود. ۱۰. رزولوشن بالایی از این روش، برای تصویربرداری از بافتهای سطحی و سلولهای نزدیک سطح پوست استفاده میشود. کاربرد درمانی (سونوتراپی): ۱. در فیزیوتراپی جهت کاهش درد و التهاب و همچنین انعطافپذیری بافتها از اولترا سوند استفاده میگردد.
۲. کاربرد گرمایی 11. تزریق بدون جراحت با جذب امواج فراصوت بهوسیله بدن بخشی از انرژی آن به گرما تبدیل میشود. گرمای موضعی حاصل از جذب امواج فراصوت بهبودی را تسریع میکند. قابلیت کشسانی کلاژن (پروتئینی ارتجاعی) را افزایش میدهد. کشش در جوشگاههای زخم (scars) افزایش میدهد و باعث بهبود آنها میشود. اگر اسکار به بافتهای زیرین خود چسبیده باشد، باعث آزاد شدن آنها میشود. گرمای حاصل از امواج فراصوت با گرمای حاصل از گرمایش متفاوت است.
میکروماساژ مکانیکی
به هنگام فشردگی و انبساط محیط، امواج طولی فراصوتی روی بافت اثر میگذارند و باعث جابجایی آب میان بافتی و در نتیجه باعث کاهش ورم (تجمع آب میان بافتی در اثر ضربه به یک محل) میشوند.
درمان آسیب تازه و ورم:آسیب تازه معمولاً با ورم همراه است. فراصوت در بسیاری از موارد برای از بین بردن مواد دفعی در اثر ضربه و کاهش خطر چسبندگی بافتها بهم بکار میرود.
درمان ورم کهنه یا مزمن: فراصوت چسبندگیهایی که میان ساختمانهای مجاور ممکن است ایجاد شود را میشکند.
خطرات فراصوت
جستجو در ویکیانبار در ویکیانبار پروندههایی دربارهٔ سونوگرافی فراصوتی موجود است.
سوختگی
اگر امواج پیوسته و در یک مکان بدون چرخش بکار روند، در بافت باعث سوختگی میشود و باید امواج حرکت داده شوند.
پارگی کروموزومی
استفاده دراز مدت از امواج اولتراسوند با شدت خیلی بالا پارگی در رشته دی ان ای (DNA) را نشان میدهد.
ایجاد حفره
یکی از عوامل کاهش انرژی امواج اولتراسوند هنگام گذشتن از بافتهای بدن ایجاد حفره یا کاویتاسیون است. همه محلولها شامل مقدار قابل ملاحظهای حبابهای گاز غیر قابل دیدن هستند و دامنه بزرگ نوسانهای امواج اولتراسوند در داخل محلولها میتواند بر روی بافتها تغییرات بیولوژیکی ایجاد کند (پارگی در دیواره یاختهها و از هم گسستن مولکولهای بزرگ).
عایق صوتی
هر وسیلهای برای کاهش فشار صوتی با توجه به صدای منبع و گیرنده را عایق صوتی (به انگلیسی: Soundproofing) میگویند.
چندین روش اساسی برای کاهش صدا وجود دارد: افزایش فاصله بین منبع و گیرنده، با استفاده از موانع سر و صدا برای منعکس یا جذب انرژی از امواج صوتی است، با استفاده از سازههای میرایی مانند تیغههای صوتی، و یا با استفاده از عایقهای صوتی.
فواید استفاده از عایق صوتی
بهبود صدا در یک اتاق (اتاق بدون پژواک)
کاهش نشت صدا به / از اتاق مجاور و یا خارج از منزل
آکوستیک آرام بخش
کاهش سر و صدا
کنترل سر و صدا
محدود کردن سر و صدای ناخواسته
عایق صوتی میتواند از امواج صوتی ناخواسته غیر مستقیم مانند سرکوب بازتاب که باعث پژواک جلوگیری کند عایق صوتی میتواند انتقال امواج ناخواسته صدای مستقیم از منبع به شنونده غیر ارادی از طریق کاهش استفاده از فاصله و دخالت اشیاء در مسیر صدا مسیر سازد
روشهای ساده عایقکاری صوتی
1. بستن منافذ ورود و خروج هوا. هر منفذی که هوا بتواند از آن عبور کند،صدا را هم می تواندانتقال دهد. کلیه منافذ موجود در سقفها و دیوارهانظیر اطراف جعبه تقسیم های برق، کانالها و داکتها ،سیم ها و هرجایی راکه شیئی از داخل دیوار یا سقف عبور می کند با بتونه یا فوم پلی اورتان درزگیری نمایید.
2. جلوگیری از ایجاد "کانالهای عبور صدا " در دیوارها. هنگام ساخت بناهای جدید ، کلیدهای برق و دریچه های هوا را در داخل دیوارمشترک دو فضا ، پشت به پشت هم قرار ندهید.
3. اجتناب از استفاده از مصالح سخت. زیرا اینگونه مصالح ,صوت را به آسانی ازیک مکان به مکان دیگر انتقال می دهند.
4. استفاده از یک لایه انعطاف پذیرنظیر فوم منبسط شونده ، جهت جدا نمودن لوله ها از غلافها یا سوراخهایی که از آن عبور می کنند.
5. استفاده از عایق صوتی در دیوارهای ساختمانهای جدید جهت جلوگیری ازانتقال صدا بین اتاقهای مجاور. به منظور جلوگیری از انتقال صدای نامطلوب جریان سریع آب به هنگام تخلیه فلاش تانک توالت، لوله های پلاستیکی تخلیه آب را عایق بندی کنید.
6. استفاده از وسایل خانگی آرامتر، حتی اگر گرانتر از موارد مشابه پرصداتر باشند.
7. جدا نمودن تجهیزات صدادار از محلهای استراحت. استفاده از اطاقهای مجزای مجهز به عایق های صوتی می تواند ایده خوبی درطراحی منزل باشد. بکارگیری درهای مجهز به عایق بین کلیه فضاها ، به مقدار قابل ملاحظه ای از انتقال صدا در خانه جلوگیری می کند.
8. استفاده از مصالح جاذب صدا در کفها، دیوارها و سقفها. عایقهای صوتی به مانند موکت می توانند از عبور صدا جلوگیری نمایند. حتی الامکان ازبکارگیری کفپوشهای سخت، مانند سرامیک، بتن و چوب خودداری نمایید.
صوتشناسی
صوتشناسی یا آکوستیک یکی از شاخههای علم فیزیک است و موضوع آن بررسی موج های مکانیکی در گازها ، مایع ها و جامدها ،از جمله نوسان ها ، صدا ، فراصوت و فروصوت است.کاربردهای آکوستیک در بسیاری از جنبه های زندگی امروز دیده می شوند و ساده ترین نمونه آن صنایع صوتی و نیز کنترل نویز (مکانیکی)است.
واژه ی آکوستیک برگرفته از ریشه ی یونانی ακουστικός ، به معنای "برای و از شنوایی" و نیز از ἀκουστός به معنای قابل شنیدن است.
تاریخچه
از نظر اهمیتی که آکوستیک یا علم صدا دارا میباشد میتوان انتظار داشت که این موضوع در تاریخ علوم فیزیک جزو مطالب اساسی به شمار رفته باشد، در صورتی که چنین چیزی نیست، زیرا در قبال تاریخ سایر علوم، تاریخ آکوستیک قسمت از قلم افتاده و مهجوری بیش نیست. یکی از دلایل این مهجوریت تاریخی این است که نظریه اساسی اصلی راجع به انتشار و اخذ صوت از زمانهای بسیار قدیم در تحولات فکر بشری پیدا شده و اسلوب این فکر همان است که امروزه مورد قبول ماست.
تولید صوت
وقتی که به یک جسم جامد ضربه وارد میسازیم، تولید صدا میکند. تحت بعضی از شرایط صدای حاصل، بگوش انسان خوش آیند و مطبوع است و این در واقع اساس پیدایش علم موسیقی است که سالیان دراز قبل از تاریخ ضبط صوت، موجود بوده است، اما موسیقی، قرنها قبل از نظر علمی مورد تحقیق قرار گیرد، جزو صنایع ظریفه محسوب میگردید. این مطلب مورد قبول عموم است که اولین فیلسوف یونانی که مبنای موسیقی را برسی نموده است. فیثاغورث میباشد که ۶ قرن قبل از میلاد زندگی میکرده است.
جهتیابی با نشانههای طبیعی
هرگونهای از درختان برشها و خصوصیات خاصّ خود را دارد. باد و آفتاب بر درختان تأثیر میگذارند و این سرنخی است برای محاسبه جهت شمال-جنوب.
این روشها خیلی قابل اطمینان نیستند. مثلاً «باد غالب» ممکن است حالت عادی را به طور قابلملاحظهای تغییر دهد و باعث تغییر و انحراف آن شود. همچنین در جنگلهای انبوه -به دلیل عدم نفوذ و رسوخ آفتاب درون آنها- برخی روشها کارا نخواهند بود. اگر از علامتهای طبیعی استفاده میکنید، برای تصمیمگیری، باید هر چند تا علامت مختلف را که میتوانید پیدا کنید.
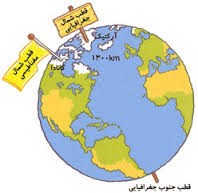
بسیاری از روشهای زیر بر اساس آفتاب هستند: در نیمکرهٔ شمالی زمین، جهت رو به جنوب در معرض آفتاب بیشتری است. تابش خورشید رشد شاخهها و برگها را زیاد میکند.
۱- جهتیابی با خزهها و گلسنگها: سمت شمالی درختان و تختهسنگها، گلسنگها و خزههای بیشتری دارد؛ چرا که نمناکتر و مرطوبتر از سمت جنوبی آنهاست.
خزه در جایی رشد میکند که دارای سایه و آب زیادی باشد؛ محلهای خنک و نمناک. تنهٔ درختان در سمت شمالی سایه و رطوبت بیشتری دارد، و در نتیجه خزهها معمولاً بیشتر در این سمت میرویند.
این روش همیشه نتیجهٔ درست به ما نمیدهد. ۱) هرچند سمت شمالی در سایهٔ بیشتری است، ولی لزوماً رطوبت سمت شمال بیشتر نیست؛ و برای رشد خزهها رطوبت مهمتر از سایه است(جایی که رطوبت در آنجا بیشتر ماندگار است). ۲) گاه ممکن است درختان و پوشش گیاهی مجاور طرف دیگر درخت را هم سایه کند. ۳) در یک اقلیم بارانی(جنگلها و بیشههای مرطوب) ممکن است همه طرف درخت نمناک باشد(یعنی خزه دور برخی درختان در همهطرف رشد کرده؛ البته معمولاً در جهت جنوب بیشتر رشد کردهاست). ۴) ممکن است باد مانع رشد خزه در طرف شمالی درخت شود. ۵) در مناطق خشک هم که اصلاً خزهای وجود ندارد!
ضمناً در نظر داشته باشید که معمولاً خزه در جهت نور آفتاب(جنوب) خرمایی رنگ است و در مکانهای سایه و مرطوب سبز یا طوسی رنگ.
۲- جهتیابی با درختان: از آنجا که سمت شمالی درختان در معرض آفتاب کمتری است، درختان در این سمتشان شاخوبرگ کمتری دارند.
به دلیل آنکه آفتاب بیشتر از سمت جنوب میتابد، درختان جنوب بهتر و بیشتر رشد میکنند. وجود درختانی مانند صنوبر سیاه و سفید، راش، بلوط، درختان آزاد، شاه بلوط هندی، افرا نروژی و درخت اقاقیا صحت این مسئله را ثابت میکند. این درختها در جنوب بیشتر دیده میشوند.
پوست درختان قدیمی در سمت رو به آفتاب(جنوب) معمولاً نازکتر است.
پوسیده بودن یک طرف از اکثر درختان جنگل، جهت شمال را به ما نشان میدهد؛ سمت پوسیده شمال است.
به خاطر نوع تابش خورشید، شاخههای جنوبی اکثر درختان افقیتر و شاخههای شمالی عمودیترند.
در کوههای سنگی، کاجهای انحناپذیر در شیب جنوبی، و صنوبرهای انگلمان در شیب شمالی میرویند.
معمولاً درختان برگ ریز در شیبهای جنوبی تپهها میرویند و سراشیبهای شمالی همیشه سبز است.
زمینِ اطراف ریشهٔ درختان، به سمت جنوب سستتر و توخالیتر از قسمت شمالی است. پس زمین به سمت شمال سفتتر بوده و به خشکی زمین جنوبی نیست.
رشد پوشش گیاهی در سمت جنوبی تپهها بیشتر از سمت شمالی خواهد بود.
۳-جهتیابی با تنهٔ درختان بریدهشده: اگر مقطع درخت بریدهشدهای را نگاه کنید، تعدادی دایرهٔ هم مرکز را مشاهده خواهید کرد، که هر یک از آنها نشان یک سال عمر درخت میباشد. درختی که بطور دائم آفتاب به تنهاش بتابد، دایرههای نشاندهنده عمر آن درخت در یک سمت به هم نزدیکتر شده و در سمت دیگر از هم دور خواهند بود. سمتی که فاصله خطوط حلقههای سنی درخت به هم نزدیکتر باشد سمت شمال را مشخص میکند، و سمتی که خطوط حلقههای سنی از هم فاصلهٔ بیشتری داشته باشد سمت جنوب را نشان میدهد؛ به علت تابش زیاد آفتاب و رشد شدیدتر آن.
۴- جهتیابی به کمک گلها و گیاهان: گیاهان، و گلهای درختان تمایل دارند رو به آفتاب قرار بگیرند؛ یعنی جنوب یا شرق.
برخی گیاهان برای جهتیابی اشتهار یافتهاند. مثلاً در آمریکا گُلی وجود دارد که همیشه جهتگیری شمالی-جنوبی دارد (رشد برگهایش به سمت خط شمال- جنوب است) و آن را «گیاه قطبنما(یا Compass Plant)» و یا «رُزینوید(Rosinweed)» میخوانند. نام علمی آن «سیلفیوم لاکینیاتوم» (Silphium laciniatum) است، و مسافران اولیهٔ این سرزمین از این گیاه برای جهتیابی استفاده میکردهاند.
اکالیپتوس استرالیایی هم گیاهی جهتیاب است. این گیاه که در سرزمینهای گرم و خشک میروید، برگهایش رو به شمال یا جنوب است.
همچنین درختی به نام «نخل رهنوردان([ یا Traveler’s Palm])» وجود دارد که محور شاخههایش شرقی-غربی اند.
همانطور که گفته شد، این که کدام طرف شرق است و کدام طرف غرب، یا کدام یک از طرفین شمال یا جنوب است را میتوان با توجه به سمت خورشید و ماه در آسمان یا روشهای دیگر یافت -ماه و خورشید تقریباً در سمت جنوبی آسمان قرار دارند.
۵- جهتیابی به کمک باد غالب: بادها را از جهتی که میوزند، نامگذاری میکنند مانند باد شمالی از شمال. هر منطقهای باد غالب و برجستهای دارد که در فصل خاص یا گاهی در تمام فصول حکمفرماست. باد غالب، باد خاصی است که وزش آن طولانیتر بوده و در جهت خاصی میوزد. با دانستن جهت بادهای غالب میتوانید چهار جهت اصلی را تشخیص دهید.
معمولاً نام باد را از جهتی که وزیدهاست، نامگذاری میکنند. مثلاً باد شمال یعنی بادی که از شمال به سمت جنوب میوزد.
برای جهتیابی به کمک باد غالب، ۱) ابتدا باید جهت باد غالب منطقه را دانست. ۲) سپس باید در جایی که هستیم جهت باد غالب را تشخیص دهیم. برای نمونه، اگر بدانیم که در منطقهٔ ما باد غالب از شرق میوزد، و ضمناً جهت باد غالب منطقه را تشخیص دهیم، طرف منشأ باد شرق خواهد بود؛ که با دانستن شرق، دیگر جهتهای اصلی هم به سادگی یافته میشوند.
نکتهٔ اول: اگر جهت باد غالب منطقهتان را نمیدانید، اطلاعات زیر ممکن است کمککار باشد:
در نواحی معتدل، باد غالب از غرب میوزد. (در هر دو نیم کره شمالی و جنوبی)
در نواحی گرمسیری، باد غالب بین مناطق شمال شرقی و جنوب شرقی جریان دارد.
در نواحی استوایی، باد غالب معمولاً از سمت شرق میوزد.
نکتهٔ دوم: جهت باد غالب منطقه را تشخیص دهیم:
در هر منطقهای باد غالب ویژگیهای خاص خود را دارد؛ مثل درجه حرارت، رطوبت و سرعت که در فصول مختلف تغییر میکند.
باد غالب بر رشد درختان و گیاهان، جهت جمع شدن برفهای باد آورنده و در جهت علفهای بلند تأثیرگذار است. در واقع باد غالب بیشترین تأثیر را بر روی جهت پوشش گیاهی، برف، ماسه یا دیگر اشیای روی سطح زمین دارد.
الف)درختان:
جهت خم شدن اغلب درختان منطقه نشان دهنده جهت وزش باد غالب منطقهاست. برای نمونه اگر درختان به طرف شمال منحرف و متمایل شدهاند، باد غالب محتملا از سمت جنوب وزیدهاست.
اثر دیگری که باد غالب بر درختان دارد این است که: در جهتی که از وزش باد در امان است، شاخ و برگ بیشتری رشد کردهاست.
در واقع باد ممکن است با صدمه زدن یا خشک کردن شاخههای جوان، رشد درخت را کند یا متوقف کند. معمولاً وزش باد، باعث کند شدن رشد درختان میشود؛ برعکسِ خورشید، که رشد شاخهها و برگها را زیاد میکند.
در زمستان باد غالب معمولاً با برف و تگرگ همراه است، که باعث شکستن شاخههای جوان میشود.
درختی که برای تعیین جهت استفاده میشود، باید در محلی باز و وسیع باشد. نباید در پناه تپه، درختان دیگر یا ساختمانها باشد. چند تا از درختان نزدیک به هم را مورد آزمایش قرار دهید. مطمئن شوید که درختان هرس نشده باشند.
از آنجا که درختان تحت تأثیر عوامل زیادی هستند، باید یافتههای خود را با مشاهدهٔ درختان متعددی در همسایگی یکدیگر تأیید کنید.
ب)ماسه و برف:
امواج ماسه در بیابانها، و امواج پستی-بلندیهای برف در مناطق قطبی جهت باد را نشان میدهند. البته گاه به خاطر آنکه این موجها خیلی کوچکاند و از چند سانتیمتر تجاوز نمیکنند، برای یافتن باد غالب نمیتوانند کمککار باشند، زیرا میتوانند با هر باد تند موضعی به سرعت تشکیل شوند.
در بیابانها انواع مختلف تلماسهها وجود دارند، که شکل آنها جهت باد غالب را نمایان میسازد؛ همچنین در مورد تلیخهای قطب: در مناطقی که به شدت پوشیده از برفاند، باد غالب تودههای برف را میراند و آنها را تبدیل به تلهای برآمدهای میسازد. این تلها از چند سانتیمتر تا یک متر ارتفاع دارند، و موازی باد غالب تشکیل میشوند. در واقع برف از لحاظ فیزیکی شبیه ماسه عمل میکند.
ج) نسیم: برخی مناطق الگوی حرکت جریان هوایشان نوسان بیشتری نسبت به جاهای دیگر دارد. مثلاً مردم کنار ساحل با نسیم دریا مأنوساند. معمولاً بعدازظهرها نسیم مداومی از طرف دریا میوزد. در شب هم معمولاً جهت نسیم برعکس میشود و از خشکی به سمت دریا میوزد. نسیم مشابهی در درهها و کوهها میوزد: در روز نسیمی از دره به سمت بالای کوه وزیدن میگیرد؛ و در شب برعکس، نسیم از بالا به سمت دره میوزد. اگر -مثلاً به کمک نقشه- بدانیم که دریا یا کوه (یا ساحل یا دره) در کدام جهتمان است، میتوانیم جهتهای اصلی را بیابیم.
د) هوای گرم و سرد: در نیمکرهٔ شمالی زمین هوایی که از شمال میآید معمولاً سردتر از هوایی است که از جنوب میآید(بادهای شمالی از بادهای جنوبی سردتر است).
هـ) سایر موارد:
اگر گمان میکنید که بادی که در لحظه میوزد باد غالب منطقهاست، میتوانید به درختان در مسیر باد نگاه کنید. با نگاه به نوک درختان میتوانید جهت باد را بفهمید.
میتوانید به تغییر جهت ابرها دقت کنید؛ بهویژه ابرهای بلندی که توسط بادهای غالب آورده میشوند.
در روی دریا و اقیانوسها بادهای غالب دارای ویژگیها و ابرهای خاص خود هستند.
۶- جهتیابی به کمک رودخانهها: بسیاری از رودها و نهرها در نیمکرهٔ شمالی زمین رو به جنوب سرازیرند، یعنی رو به استوا. این روند عمومی رودهاست، ولی همیشه درست نیست. مثلاً رود نیل -که تماماً در نیمکرهٔ شمالی است- به سوی شمال جریان دارد و به مدیترانه میریزد.
۷- جهتیابی به کمک حیوانات و حشرات:
مورچهها خاکِ لانهٔ خود را به سمت جنوب یا شرق میریزند. مورچهها چنین میکنند تا در هنگام روز خاکریزشان به عنوان سایهبانی برایشان عمل کند، تا راحتتر کار خود را انجام دهند.
مورچهها خانههای خود(مورتپهها) را بر روی شیبهای جنوب شرقی میسازند؛ زیرا خورشید در پاییز و زمستان بیشتر به این قسمتها میتابد. آنها مورتپههای خود را نزدیک درختان و صخرههای جنوبی و جنوب شرقی بنا میکنند.
اگر شما در کنار برکه یا دریاچهای باشید که پرندگان، ماهیان یا دوزیستان در حال تولیدمثل هستند، در نظر داشته باشید که آنها معمولاً ترجیح میدهند در سمت غربی زاد و ولد (تولیدمثل و پرورش) نمایند.
دارکوب(شانهبهسر) معمولاً حفرههایش را در سمت شرقی درخت حفر میکند.
سنجابها هم معمولاً در سوراخهای سمت شرقیِ درختان خانه و لانه میگزینند.
۸- جهتیابی به کمک خانههای شهری: امروزه معمولاً خانهها را به موازات شمال -جنوب یا شرق-غرب میسازند؛ یعنی نسبت به جهتهای اصلی مورب نمیسازند. این میتواند در تنظیم صحیح جهتها و تصحیح روشهای تقریبی بالا کمککار باشد. باید توجه کرد که در بسیاری موارد این اصل رعایت نشدهاست.
قطب مغناطیسی شمال
قطبهای مغناطیسی یعنی جایی که خطوط میدان مغناطیسی به صورت واگرا از زمین خارج (جنوب مغناطیسی) و یا به صورت همگرا به آن وارد (شمال مغناطیسی) میشوند.
عقربه قطبنما -به عنوان یک وسیله مغناطیسی (یک آهنربا)- وقتی که آزادانه معلق شود، قطبهای مغناطیسی را یافته و در جهت آنها آرایش میگیرد؛ یعنی جایی که عموماً شمال حقیقی نیست (بهجز برخی مناطق کره زمین). زاویه بین شمال حقیقی و شمال مغناطیسی، «میل مغناطیسی» نامیده میشود.
قطبهای مغناطیسی زمین در طول زمان تغییر میکنند. قطب شمال مغناطیسی در سال ۲۰۰۱ در موقعیت ۸۱٫۳ درجه شمالی و ۱۱۰٫۸ درجه غربی، در سال ۲۰۰۵ در موقعیت ۸۳٫۱ درجه شمالی و ۱۱۷٫۸ درجه غربی و در سال ۲۰۰۹ در موقعیت ۸۴٫۹ درجه شمالی و ۱۳۱٫۰ درجه غربی بودهاست. در سال ۲۰۱۲ قطب مغناطیسی شمال در موقعیت ۸۵٫۹ درجه شمالی و ۱۴۷٫۰ درجه غربی قرار گرفت.
هر ۲۵ هزار سال، قطبهای مغناطیسی یک دور کامل میزنند.
قطب شمال مغناطیسی، سالانه ۷٫۳۴ کیلومتر جابهجا میشود.
انحراف مغناطیسی
انحراف مغناطیسی خطای ناشی از تأثیرات جاذبههای مغناطیسی موضعی و منطقهای (مانند فلز و الکتریسیته) ااست، که باید در کنار میل مغناطیسی در نظر گرفته شود. هر گاه قطبنما در نزدیکی اشیای آهنی یا فولادی و یا منابع الکتریکی قرار گرفته باشد، عقربهاش از جهت قطب مقداری منحرف میشود. کلاً به همراه داشتن اشیایی از جنس آهن یا انواع مشابه آن میتواند باعث اختلال در حرکت عقربه شود. حتی وجود یک گیره کاغذ روی نقشه ممکن است مساله ساز شود. بنابراین، هنگام استفاده از قطبنما باید مطمئن شویم که از اشیای انحرافدهنده آن، بهطور کلی دور است. همچنین احتمال تأثیرگذاری جاذبههای مغناطیسی موجود در خاک نیز وجود دارد، که بسیار نادر است؛ ولی در مکانهایی که مثلاً معدن آهن وجود دارد باید در نظر گرفته شود.
میل مغناطیسی
انحراف مغناطیسی یا تغییر مغناطیسی یا میل مغناطیسی زاویه بین نصف النهار مغناطیسی و نصف النهار جغرافیایی در هر نقطه از سطح زمین است.
میل مغناطیسی، در هر نقطه از زمین، زاویه بین شمال حقیقی و شمال مغناطیسی در آن نقطه است؛ یعنی زاویهٔ بین سمتی که عقربهٔ قطبنما نشان میدهد، و سمت شمال جغرافیایی. منابع مختلف میل مغناطیسی را «شیب مغناطیسی» یا «تنزل مغناطیسی» یا «تغییر مغناطیسی» هم مینامند. برخی به آن انحراف مغناطیسی هم گفتهاند، ولی دیگران این واژه را برای انحراف عقربهٔ قطبنما در اثر عوامل محیطی (مانند وسایل آهنی و منابع الکتریکی و غیره) مناسبتر میدانند.
میل مغناطیسی با موقعیت، زمان (سالانه و روزانه)، ناهنجاریهای مغناطیسی محلی، ارتفاع (جزئی و قابل صرف نظر) و فعالیتهای مغناطیسی خورشید تغییر میکند. میل مغناطیسی در طول خطوطی &mdash؛ که اصطلاحا خطوط هم ارز∗ نامیده میشوند &mdash؛ ثابت است. خط فرضی با میل مغناطیسی صفر درجه در حال حاضر از غرب خلیج هودسن، دریاچه سوپریور، دریاچه میشیگان و فلوریدا عبور میکند.
تعیین میل مغناطیسی
اگر عقربه قطبنما شرق یا غربِ شمال واقعی را به عنوان شمال مشخص نماید، این اختلاف به ترتیب میل مغناطیسی شرقی یا غربی نامیده میشود. شمال مغناطیسی هم در نیمکره شمالی و هم در نیمکره جنوبی به عنوان مرجع میل مغناطیسی است. مقدار زاویهٔ انحراف بستگی با محل آزمایش دارد. برای تعیین میل مغناطیسی در یک منطقه مورد نظر میتوان از موارد زیر استفاده کرد:
نقشههای توپوگرافی چاپ شده: این نقشه ها با اندازه گیری های متعدد میل مغناطیسی در نقاط مختلف کرهٔ زمین تهیه می شوند. در برخی نقشهها میل مغناطیسی منطقه به وسیله زاویه بین دو پیکان شمال مغناطیسی (MN) و شمال حقیقی (GN) نشان داده شده است.
نمودارهای خطوط همارز چاپ شده و یا موجود در وبگاهها، که میل مغناطیسی را نشان میدهند.
حسابگر آنلاین برای مشخص نمودن آخرین میل مغناطیسی، برای یک موقعیت مشخص (طول و عرض جغرافیایی) و زمان مشخص.
لازم به ذکر است که در یک محل مقدار زاویهٔ انحراف برحسب زمان اندکی تغییر میکند و اندازهٔ آن در نقاط مختلف زمین متفاوت است.
در ایران میل مغناطیسی به سمت شرق است و مقدار زاویه آن در مکانهای مختلف متفاوت است. برای نمونه در ۱۲ خردادماه سال ۱۳۸۶ میل مغناطیسی تهران &mdash؛ طبق محاسبات &mdash؛ برابر ۴ درجه و چهار دقیقه به سمت شرق بودهاست، که هر سال نزدیک چهار دقیقه (کمتر از یکدهم درجه) به سمت شرق افزایش پیدا میکند.
مثال
چنانچه به کمک عقربهٔ مغناطیسی به طرف قطب شمال یا جنوب برویم، به قطب شمال و جنوب واقعی کرهٔ زمین نمیرسیم. علت این است که قطب شمال و جنوب جغرافیایی و مغناطیسی کرهٔ زمین، با هم یکی نیست؛ یعنی اینکه قطب شمال مغناطیسی زمین، درست روی قطب شمال جغرافیایی زمین قرار ندارد و اگر دو قطب جغرافیایی و مغناطیسی زمین را توسط خطی فرضی به به نام محور به هم وصل کنیم، بین دو محور مغناطیسی و محور جغرافیایی زمین، زاویهای ساخته میشود که به آن، زاویهٔ میل مغناطیسی گویند.
هرگونهای از درختان برشها و خصوصیات خاصّ خود را دارد. باد و آفتاب بر درختان تأثیر میگذارند و این سرنخی است برای محاسبه جهت شمال-جنوب.
این روشها خیلی قابل اطمینان نیستند. مثلاً «باد غالب» ممکن است حالت عادی را به طور قابلملاحظهای تغییر دهد و باعث تغییر و انحراف آن شود. همچنین در جنگلهای انبوه -به دلیل عدم نفوذ و رسوخ آفتاب درون آنها- برخی روشها کارا نخواهند بود. اگر از علامتهای طبیعی استفاده میکنید، برای تصمیمگیری، باید هر چند تا علامت مختلف را که میتوانید پیدا کنید.
بسیاری از روشهای زیر بر اساس آفتاب هستند: در نیمکرهٔ شمالی زمین، جهت رو به جنوب در معرض آفتاب بیشتری است. تابش خورشید رشد شاخهها و برگها را زیاد میکند.
۱- جهتیابی با خزهها و گلسنگها: سمت شمالی درختان و تختهسنگها، گلسنگها و خزههای بیشتری دارد؛ چرا که نمناکتر و مرطوبتر از سمت جنوبی آنهاست.
خزه در جایی رشد میکند که دارای سایه و آب زیادی باشد؛ محلهای خنک و نمناک. تنهٔ درختان در سمت شمالی سایه و رطوبت بیشتری دارد، و در نتیجه خزهها معمولاً بیشتر در این سمت میرویند.
این روش همیشه نتیجهٔ درست به ما نمیدهد. ۱) هرچند سمت شمالی در سایهٔ بیشتری است، ولی لزوماً رطوبت سمت شمال بیشتر نیست؛ و برای رشد خزهها رطوبت مهمتر از سایه است(جایی که رطوبت در آنجا بیشتر ماندگار است). ۲) گاه ممکن است درختان و پوشش گیاهی مجاور طرف دیگر درخت را هم سایه کند. ۳) در یک اقلیم بارانی(جنگلها و بیشههای مرطوب) ممکن است همه طرف درخت نمناک باشد(یعنی خزه دور برخی درختان در همهطرف رشد کرده؛ البته معمولاً در جهت جنوب بیشتر رشد کردهاست). ۴) ممکن است باد مانع رشد خزه در طرف شمالی درخت شود. ۵) در مناطق خشک هم که اصلاً خزهای وجود ندارد!
ضمناً در نظر داشته باشید که معمولاً خزه در جهت نور آفتاب(جنوب) خرمایی رنگ است و در مکانهای سایه و مرطوب سبز یا طوسی رنگ.
۲- جهتیابی با درختان: از آنجا که سمت شمالی درختان در معرض آفتاب کمتری است، درختان در این سمتشان شاخوبرگ کمتری دارند.
به دلیل آنکه آفتاب بیشتر از سمت جنوب میتابد، درختان جنوب بهتر و بیشتر رشد میکنند. وجود درختانی مانند صنوبر سیاه و سفید، راش، بلوط، درختان آزاد، شاه بلوط هندی، افرا نروژی و درخت اقاقیا صحت این مسئله را ثابت میکند. این درختها در جنوب بیشتر دیده میشوند.
پوست درختان قدیمی در سمت رو به آفتاب(جنوب) معمولاً نازکتر است.
پوسیده بودن یک طرف از اکثر درختان جنگل، جهت شمال را به ما نشان میدهد؛ سمت پوسیده شمال است.
به خاطر نوع تابش خورشید، شاخههای جنوبی اکثر درختان افقیتر و شاخههای شمالی عمودیترند.
در کوههای سنگی، کاجهای انحناپذیر در شیب جنوبی، و صنوبرهای انگلمان در شیب شمالی میرویند.
معمولاً درختان برگ ریز در شیبهای جنوبی تپهها میرویند و سراشیبهای شمالی همیشه سبز است.
زمینِ اطراف ریشهٔ درختان، به سمت جنوب سستتر و توخالیتر از قسمت شمالی است. پس زمین به سمت شمال سفتتر بوده و به خشکی زمین جنوبی نیست.
رشد پوشش گیاهی در سمت جنوبی تپهها بیشتر از سمت شمالی خواهد بود.
۳-جهتیابی با تنهٔ درختان بریدهشده: اگر مقطع درخت بریدهشدهای را نگاه کنید، تعدادی دایرهٔ هم مرکز را مشاهده خواهید کرد، که هر یک از آنها نشان یک سال عمر درخت میباشد. درختی که بطور دائم آفتاب به تنهاش بتابد، دایرههای نشاندهنده عمر آن درخت در یک سمت به هم نزدیکتر شده و در سمت دیگر از هم دور خواهند بود. سمتی که فاصله خطوط حلقههای سنی درخت به هم نزدیکتر باشد سمت شمال را مشخص میکند، و سمتی که خطوط حلقههای سنی از هم فاصلهٔ بیشتری داشته باشد سمت جنوب را نشان میدهد؛ به علت تابش زیاد آفتاب و رشد شدیدتر آن.
۴- جهتیابی به کمک گلها و گیاهان: گیاهان، و گلهای درختان تمایل دارند رو به آفتاب قرار بگیرند؛ یعنی جنوب یا شرق.
برخی گیاهان برای جهتیابی اشتهار یافتهاند. مثلاً در آمریکا گُلی وجود دارد که همیشه جهتگیری شمالی-جنوبی دارد (رشد برگهایش به سمت خط شمال- جنوب است) و آن را «گیاه قطبنما(یا Compass Plant)» و یا «رُزینوید(Rosinweed)» میخوانند. نام علمی آن «سیلفیوم لاکینیاتوم» (Silphium laciniatum) است، و مسافران اولیهٔ این سرزمین از این گیاه برای جهتیابی استفاده میکردهاند.
اکالیپتوس استرالیایی هم گیاهی جهتیاب است. این گیاه که در سرزمینهای گرم و خشک میروید، برگهایش رو به شمال یا جنوب است.
همچنین درختی به نام «نخل رهنوردان([ یا Traveler’s Palm])» وجود دارد که محور شاخههایش شرقی-غربی اند.
همانطور که گفته شد، این که کدام طرف شرق است و کدام طرف غرب، یا کدام یک از طرفین شمال یا جنوب است را میتوان با توجه به سمت خورشید و ماه در آسمان یا روشهای دیگر یافت -ماه و خورشید تقریباً در سمت جنوبی آسمان قرار دارند.
۵- جهتیابی به کمک باد غالب: بادها را از جهتی که میوزند، نامگذاری میکنند مانند باد شمالی از شمال. هر منطقهای باد غالب و برجستهای دارد که در فصل خاص یا گاهی در تمام فصول حکمفرماست. باد غالب، باد خاصی است که وزش آن طولانیتر بوده و در جهت خاصی میوزد. با دانستن جهت بادهای غالب میتوانید چهار جهت اصلی را تشخیص دهید.
معمولاً نام باد را از جهتی که وزیدهاست، نامگذاری میکنند. مثلاً باد شمال یعنی بادی که از شمال به سمت جنوب میوزد.
برای جهتیابی به کمک باد غالب، ۱) ابتدا باید جهت باد غالب منطقه را دانست. ۲) سپس باید در جایی که هستیم جهت باد غالب را تشخیص دهیم. برای نمونه، اگر بدانیم که در منطقهٔ ما باد غالب از شرق میوزد، و ضمناً جهت باد غالب منطقه را تشخیص دهیم، طرف منشأ باد شرق خواهد بود؛ که با دانستن شرق، دیگر جهتهای اصلی هم به سادگی یافته میشوند.
نکتهٔ اول: اگر جهت باد غالب منطقهتان را نمیدانید، اطلاعات زیر ممکن است کمککار باشد:
در نواحی معتدل، باد غالب از غرب میوزد. (در هر دو نیم کره شمالی و جنوبی)
در نواحی گرمسیری، باد غالب بین مناطق شمال شرقی و جنوب شرقی جریان دارد.
در نواحی استوایی، باد غالب معمولاً از سمت شرق میوزد.
نکتهٔ دوم: جهت باد غالب منطقه را تشخیص دهیم:
در هر منطقهای باد غالب ویژگیهای خاص خود را دارد؛ مثل درجه حرارت، رطوبت و سرعت که در فصول مختلف تغییر میکند.
باد غالب بر رشد درختان و گیاهان، جهت جمع شدن برفهای باد آورنده و در جهت علفهای بلند تأثیرگذار است. در واقع باد غالب بیشترین تأثیر را بر روی جهت پوشش گیاهی، برف، ماسه یا دیگر اشیای روی سطح زمین دارد.
الف)درختان:
جهت خم شدن اغلب درختان منطقه نشان دهنده جهت وزش باد غالب منطقهاست. برای نمونه اگر درختان به طرف شمال منحرف و متمایل شدهاند، باد غالب محتملا از سمت جنوب وزیدهاست.
اثر دیگری که باد غالب بر درختان دارد این است که: در جهتی که از وزش باد در امان است، شاخ و برگ بیشتری رشد کردهاست.
در واقع باد ممکن است با صدمه زدن یا خشک کردن شاخههای جوان، رشد درخت را کند یا متوقف کند. معمولاً وزش باد، باعث کند شدن رشد درختان میشود؛ برعکسِ خورشید، که رشد شاخهها و برگها را زیاد میکند.
در زمستان باد غالب معمولاً با برف و تگرگ همراه است، که باعث شکستن شاخههای جوان میشود.
درختی که برای تعیین جهت استفاده میشود، باید در محلی باز و وسیع باشد. نباید در پناه تپه، درختان دیگر یا ساختمانها باشد. چند تا از درختان نزدیک به هم را مورد آزمایش قرار دهید. مطمئن شوید که درختان هرس نشده باشند.
از آنجا که درختان تحت تأثیر عوامل زیادی هستند، باید یافتههای خود را با مشاهدهٔ درختان متعددی در همسایگی یکدیگر تأیید کنید.
ب)ماسه و برف:
امواج ماسه در بیابانها، و امواج پستی-بلندیهای برف در مناطق قطبی جهت باد را نشان میدهند. البته گاه به خاطر آنکه این موجها خیلی کوچکاند و از چند سانتیمتر تجاوز نمیکنند، برای یافتن باد غالب نمیتوانند کمککار باشند، زیرا میتوانند با هر باد تند موضعی به سرعت تشکیل شوند.
در بیابانها انواع مختلف تلماسهها وجود دارند، که شکل آنها جهت باد غالب را نمایان میسازد؛ همچنین در مورد تلیخهای قطب: در مناطقی که به شدت پوشیده از برفاند، باد غالب تودههای برف را میراند و آنها را تبدیل به تلهای برآمدهای میسازد. این تلها از چند سانتیمتر تا یک متر ارتفاع دارند، و موازی باد غالب تشکیل میشوند. در واقع برف از لحاظ فیزیکی شبیه ماسه عمل میکند.
ج) نسیم: برخی مناطق الگوی حرکت جریان هوایشان نوسان بیشتری نسبت به جاهای دیگر دارد. مثلاً مردم کنار ساحل با نسیم دریا مأنوساند. معمولاً بعدازظهرها نسیم مداومی از طرف دریا میوزد. در شب هم معمولاً جهت نسیم برعکس میشود و از خشکی به سمت دریا میوزد. نسیم مشابهی در درهها و کوهها میوزد: در روز نسیمی از دره به سمت بالای کوه وزیدن میگیرد؛ و در شب برعکس، نسیم از بالا به سمت دره میوزد. اگر -مثلاً به کمک نقشه- بدانیم که دریا یا کوه (یا ساحل یا دره) در کدام جهتمان است، میتوانیم جهتهای اصلی را بیابیم.
د) هوای گرم و سرد: در نیمکرهٔ شمالی زمین هوایی که از شمال میآید معمولاً سردتر از هوایی است که از جنوب میآید(بادهای شمالی از بادهای جنوبی سردتر است).
هـ) سایر موارد:
اگر گمان میکنید که بادی که در لحظه میوزد باد غالب منطقهاست، میتوانید به درختان در مسیر باد نگاه کنید. با نگاه به نوک درختان میتوانید جهت باد را بفهمید.
میتوانید به تغییر جهت ابرها دقت کنید؛ بهویژه ابرهای بلندی که توسط بادهای غالب آورده میشوند.
در روی دریا و اقیانوسها بادهای غالب دارای ویژگیها و ابرهای خاص خود هستند.
۶- جهتیابی به کمک رودخانهها: بسیاری از رودها و نهرها در نیمکرهٔ شمالی زمین رو به جنوب سرازیرند، یعنی رو به استوا. این روند عمومی رودهاست، ولی همیشه درست نیست. مثلاً رود نیل -که تماماً در نیمکرهٔ شمالی است- به سوی شمال جریان دارد و به مدیترانه میریزد.
۷- جهتیابی به کمک حیوانات و حشرات:
مورچهها خاکِ لانهٔ خود را به سمت جنوب یا شرق میریزند. مورچهها چنین میکنند تا در هنگام روز خاکریزشان به عنوان سایهبانی برایشان عمل کند، تا راحتتر کار خود را انجام دهند.
مورچهها خانههای خود(مورتپهها) را بر روی شیبهای جنوب شرقی میسازند؛ زیرا خورشید در پاییز و زمستان بیشتر به این قسمتها میتابد. آنها مورتپههای خود را نزدیک درختان و صخرههای جنوبی و جنوب شرقی بنا میکنند.
اگر شما در کنار برکه یا دریاچهای باشید که پرندگان، ماهیان یا دوزیستان در حال تولیدمثل هستند، در نظر داشته باشید که آنها معمولاً ترجیح میدهند در سمت غربی زاد و ولد (تولیدمثل و پرورش) نمایند.
دارکوب(شانهبهسر) معمولاً حفرههایش را در سمت شرقی درخت حفر میکند.
سنجابها هم معمولاً در سوراخهای سمت شرقیِ درختان خانه و لانه میگزینند.
۸- جهتیابی به کمک خانههای شهری: امروزه معمولاً خانهها را به موازات شمال -جنوب یا شرق-غرب میسازند؛ یعنی نسبت به جهتهای اصلی مورب نمیسازند. این میتواند در تنظیم صحیح جهتها و تصحیح روشهای تقریبی بالا کمککار باشد. باید توجه کرد که در بسیاری موارد این اصل رعایت نشدهاست.
قطب مغناطیسی شمال
قطبهای مغناطیسی یعنی جایی که خطوط میدان مغناطیسی به صورت واگرا از زمین خارج (جنوب مغناطیسی) و یا به صورت همگرا به آن وارد (شمال مغناطیسی) میشوند.
عقربه قطبنما -به عنوان یک وسیله مغناطیسی (یک آهنربا)- وقتی که آزادانه معلق شود، قطبهای مغناطیسی را یافته و در جهت آنها آرایش میگیرد؛ یعنی جایی که عموماً شمال حقیقی نیست (بهجز برخی مناطق کره زمین). زاویه بین شمال حقیقی و شمال مغناطیسی، «میل مغناطیسی» نامیده میشود.
قطبهای مغناطیسی زمین در طول زمان تغییر میکنند. قطب شمال مغناطیسی در سال ۲۰۰۱ در موقعیت ۸۱٫۳ درجه شمالی و ۱۱۰٫۸ درجه غربی، در سال ۲۰۰۵ در موقعیت ۸۳٫۱ درجه شمالی و ۱۱۷٫۸ درجه غربی و در سال ۲۰۰۹ در موقعیت ۸۴٫۹ درجه شمالی و ۱۳۱٫۰ درجه غربی بودهاست. در سال ۲۰۱۲ قطب مغناطیسی شمال در موقعیت ۸۵٫۹ درجه شمالی و ۱۴۷٫۰ درجه غربی قرار گرفت.
هر ۲۵ هزار سال، قطبهای مغناطیسی یک دور کامل میزنند.
قطب شمال مغناطیسی، سالانه ۷٫۳۴ کیلومتر جابهجا میشود.
انحراف مغناطیسی
انحراف مغناطیسی خطای ناشی از تأثیرات جاذبههای مغناطیسی موضعی و منطقهای (مانند فلز و الکتریسیته) ااست، که باید در کنار میل مغناطیسی در نظر گرفته شود. هر گاه قطبنما در نزدیکی اشیای آهنی یا فولادی و یا منابع الکتریکی قرار گرفته باشد، عقربهاش از جهت قطب مقداری منحرف میشود. کلاً به همراه داشتن اشیایی از جنس آهن یا انواع مشابه آن میتواند باعث اختلال در حرکت عقربه شود. حتی وجود یک گیره کاغذ روی نقشه ممکن است مساله ساز شود. بنابراین، هنگام استفاده از قطبنما باید مطمئن شویم که از اشیای انحرافدهنده آن، بهطور کلی دور است. همچنین احتمال تأثیرگذاری جاذبههای مغناطیسی موجود در خاک نیز وجود دارد، که بسیار نادر است؛ ولی در مکانهایی که مثلاً معدن آهن وجود دارد باید در نظر گرفته شود.
میل مغناطیسی
انحراف مغناطیسی یا تغییر مغناطیسی یا میل مغناطیسی زاویه بین نصف النهار مغناطیسی و نصف النهار جغرافیایی در هر نقطه از سطح زمین است.
میل مغناطیسی، در هر نقطه از زمین، زاویه بین شمال حقیقی و شمال مغناطیسی در آن نقطه است؛ یعنی زاویهٔ بین سمتی که عقربهٔ قطبنما نشان میدهد، و سمت شمال جغرافیایی. منابع مختلف میل مغناطیسی را «شیب مغناطیسی» یا «تنزل مغناطیسی» یا «تغییر مغناطیسی» هم مینامند. برخی به آن انحراف مغناطیسی هم گفتهاند، ولی دیگران این واژه را برای انحراف عقربهٔ قطبنما در اثر عوامل محیطی (مانند وسایل آهنی و منابع الکتریکی و غیره) مناسبتر میدانند.
میل مغناطیسی با موقعیت، زمان (سالانه و روزانه)، ناهنجاریهای مغناطیسی محلی، ارتفاع (جزئی و قابل صرف نظر) و فعالیتهای مغناطیسی خورشید تغییر میکند. میل مغناطیسی در طول خطوطی &mdash؛ که اصطلاحا خطوط هم ارز∗ نامیده میشوند &mdash؛ ثابت است. خط فرضی با میل مغناطیسی صفر درجه در حال حاضر از غرب خلیج هودسن، دریاچه سوپریور، دریاچه میشیگان و فلوریدا عبور میکند.
تعیین میل مغناطیسی
اگر عقربه قطبنما شرق یا غربِ شمال واقعی را به عنوان شمال مشخص نماید، این اختلاف به ترتیب میل مغناطیسی شرقی یا غربی نامیده میشود. شمال مغناطیسی هم در نیمکره شمالی و هم در نیمکره جنوبی به عنوان مرجع میل مغناطیسی است. مقدار زاویهٔ انحراف بستگی با محل آزمایش دارد. برای تعیین میل مغناطیسی در یک منطقه مورد نظر میتوان از موارد زیر استفاده کرد:
نقشههای توپوگرافی چاپ شده: این نقشه ها با اندازه گیری های متعدد میل مغناطیسی در نقاط مختلف کرهٔ زمین تهیه می شوند. در برخی نقشهها میل مغناطیسی منطقه به وسیله زاویه بین دو پیکان شمال مغناطیسی (MN) و شمال حقیقی (GN) نشان داده شده است.
نمودارهای خطوط همارز چاپ شده و یا موجود در وبگاهها، که میل مغناطیسی را نشان میدهند.
حسابگر آنلاین برای مشخص نمودن آخرین میل مغناطیسی، برای یک موقعیت مشخص (طول و عرض جغرافیایی) و زمان مشخص.
لازم به ذکر است که در یک محل مقدار زاویهٔ انحراف برحسب زمان اندکی تغییر میکند و اندازهٔ آن در نقاط مختلف زمین متفاوت است.
در ایران میل مغناطیسی به سمت شرق است و مقدار زاویه آن در مکانهای مختلف متفاوت است. برای نمونه در ۱۲ خردادماه سال ۱۳۸۶ میل مغناطیسی تهران &mdash؛ طبق محاسبات &mdash؛ برابر ۴ درجه و چهار دقیقه به سمت شرق بودهاست، که هر سال نزدیک چهار دقیقه (کمتر از یکدهم درجه) به سمت شرق افزایش پیدا میکند.
مثال
چنانچه به کمک عقربهٔ مغناطیسی به طرف قطب شمال یا جنوب برویم، به قطب شمال و جنوب واقعی کرهٔ زمین نمیرسیم. علت این است که قطب شمال و جنوب جغرافیایی و مغناطیسی کرهٔ زمین، با هم یکی نیست؛ یعنی اینکه قطب شمال مغناطیسی زمین، درست روی قطب شمال جغرافیایی زمین قرار ندارد و اگر دو قطب جغرافیایی و مغناطیسی زمین را توسط خطی فرضی به به نام محور به هم وصل کنیم، بین دو محور مغناطیسی و محور جغرافیایی زمین، زاویهای ساخته میشود که به آن، زاویهٔ میل مغناطیسی گویند.